There are many reasons to reinstall hyperion prducts when you get with a trouble.
The steps:
1. Stop all of hyperion services
2. Run uninstall Hyperion
3. Delete the Hyperion registries, this is very important, you cannot just simple run reinstall without clear the Hyperion registries.
regedit -> delete all of the entries inside Hyperion Solution, and other 2 hyperion items below Oracle
4. Delete all of the related Hyperion Environment Variables by right click Computer. For the path variable, you can edit it and delete all hyperion related entries, but don;t delete the entries for other applications.
5. Then you can go ahead to reinstall.
Have a fun!
5/12/10
install Hyperion 11.1.2 in Windows 2008
The steps of Install Hyperion 11.1.2 in Windows 2008 64bit:
1. Install the IIS service in windows OS
2. Install Oracle database(or other database), select shared mode instead of dedicated mode. By default, the dedicated mode will allow 150 process thread simultaneously, and you is not enough for Hyperion services.
Create an Oracle user name for the installation.
3. For Oracle, you just need to create one database instance, no need to create many databases, but you can create many user schemas. In a word, Oracle, one database,multi user schemas.
4. For SQL database, you can create many databases but one user id. In a word, SQL, one user id, multi databases.
5. Download Hyperion 64 bit software, extracted them in one folder
6. For the previous version Hyperion 11.1.1.3, you may install weblogic before install Hyperion products. And in Hyperion 11.1.1.3, weblogic 64bit has to be configured manully. In Hyperion 11.1.1.3, you may use weblogic 32bit on 64bit windows machine.
7. For the new Hyperion 11.1.2 version, no need to install weblogic before install hyperion, because weblogic has become a part of foundation services, and it will be installed by default.
8. Run as administrator to the install hyperion, after installation, no need to reboot computer
9. After installation go to configure shared service first, after it is successful,then confirgure all of others.
1. Install the IIS service in windows OS
2. Install Oracle database(or other database), select shared mode instead of dedicated mode. By default, the dedicated mode will allow 150 process thread simultaneously, and you is not enough for Hyperion services.
Create an Oracle user name for the installation.
3. For Oracle, you just need to create one database instance, no need to create many databases, but you can create many user schemas. In a word, Oracle, one database,multi user schemas.
4. For SQL database, you can create many databases but one user id. In a word, SQL, one user id, multi databases.
5. Download Hyperion 64 bit software, extracted them in one folder
6. For the previous version Hyperion 11.1.1.3, you may install weblogic before install Hyperion products. And in Hyperion 11.1.1.3, weblogic 64bit has to be configured manully. In Hyperion 11.1.1.3, you may use weblogic 32bit on 64bit windows machine.
7. For the new Hyperion 11.1.2 version, no need to install weblogic before install hyperion, because weblogic has become a part of foundation services, and it will be installed by default.
8. Run as administrator to the install hyperion, after installation, no need to reboot computer
9. After installation go to configure shared service first, after it is successful,then confirgure all of others.
4/12/10
Start remote Hyperion in sequence
REM Remote Start Hyperion Service
REM Description: for remote service, use
REM sc \\machine start
@ECHO OFF
REM -------STARTING Hyperion Services----------------------------
REM -------HyperionRMIRegistry--------------------------------------
sc \\machine start "Hyperion RMI Registry"
waitfor NONEXISTINGSIGNAL /T 5
REM -------Hyperion OpenLDAP--------------------------------------
sc \\machine start "Hyperion Foundation OpenLDAP"
waitfor NONEXISTINGSIGNAL /T 5
REM -------Hyperion Shared Services Web application-----------------
sc \\machine start HyS9SharedServices
waitfor NONEXISTINGSIGNAL /T 30
REM ------starting Essbase Server ----------
sc \\machine start "Hyperion Essbase Services 11.1.1 - hypservice_1"
waitfor NONEXISTINGSIGNAL /T 5
REM ------starting Essbase ADM ----------
sc \\machine start "Hyperion Administration Services - Web Application"
waitfor NONEXISTINGSIGNAL /T 5
REM --------starting integration -------
sc \\machine start "Hyperion Integration Services"
waitfor NONEXISTINGSIGNAL /T 5
REM -------Hyperion Provider Services Web application----------------
sc \\machine start HyS9aps
waitfor NONEXISTINGSIGNAL /T 5
REM --------starting workspace-----------------
sc \\machine start "Hyperion Workspace - Web Application"
waitfor NONEXISTINGSIGNAL /T 5
sc \\machine start "Hyperion Workspace - Agent Service"
waitfor NONEXISTINGSIGNAL /T 5
sc \\machine start "Hyperion Annotation Server"
waitfor NONEXISTINGSIGNAL /T 5
REM -------------starting Planning-------
sc \\machine start "Hyperion Planning - Web Application"
waitfor NONEXISTINGSIGNAL /T 10
REM --------starting EPMA Core Services-------------
REM ---the next 4 services will be started by Process manager automatically---
REM Hyperion EPM Architect - .Net JNI Bridge
REM Hyperion EPM Architect - Engine Manager
REM Hyperion EPM Architect - Event Manager
REM Hyperion EPM Architect - Job Manager
sc \\machine start "Hyperion EPM Architect - Process Manager"
waitfor NONEXISTINGSIGNAL /T 60
REM --------starting EPMA Architect-------------
sc \\machine start "Hyperion EPM Architect - Web Application"
REM waitfor NONEXISTINGSIGNAL /T 10
sc \\machine start "Hyperion EPM Architect Data Synchronization - Web Application"
REM waitfor NONEXISTINGSIGNAL /T 10
sc \\machine start "Hyperion CALC Manager - Web Application"
REM waitfor NONEXISTINGSIGNAL /T 10
REM -------Hyperion Financial Reporting Java RMI Registry------------------
sc \\machine start HyS9FRRMI
waitfor NONEXISTINGSIGNAL /T 2
REM -------Hyperion Financial Reporting Print Server----------------------------
sc \\machine start HyS9FRPrint
waitfor NONEXISTINGSIGNAL /T 2
REM -------Hyperion Financial Reporting Report Server---------------------------
sc \\machine start HyS9FRReport
waitfor NONEXISTINGSIGNAL /T 2
REM -------Hyperion Financial Reporting Scheduler Server------------------------
sc \\machine start HyS9FRSched
waitfor NONEXISTINGSIGNAL /T 2
REM -------Hyperion Financial Reporting Web application-------------------------
sc \\machine start HyS9FRWeb
waitfor NONEXISTINGSIGNAL /T 5
REM -------starting web analysis ------------------
sc \\machine start "Hyperion Web Analysis - Web Application"
REM waitfor NONEXISTINGSIGNAL /T 5
REM -------Hyperion Workspace Web application(Weblogic is included already---------------------------
REM -------The registry path refers this service to start weblogic -------------------
sc \\machine start HyS9Workspace
waitfor NONEXISTINGSIGNAL /T 20
REM ALL DONE!
waitfor NONEXISTINGSIGNAL /T 30
REM Description: for remote service, use
REM sc \\machine start
@ECHO OFF
REM -------STARTING Hyperion Services----------------------------
REM -------HyperionRMIRegistry--------------------------------------
sc \\machine start "Hyperion RMI Registry"
waitfor NONEXISTINGSIGNAL /T 5
REM -------Hyperion OpenLDAP--------------------------------------
sc \\machine start "Hyperion Foundation OpenLDAP"
waitfor NONEXISTINGSIGNAL /T 5
REM -------Hyperion Shared Services Web application-----------------
sc \\machine start HyS9SharedServices
waitfor NONEXISTINGSIGNAL /T 30
REM ------starting Essbase Server ----------
sc \\machine start "Hyperion Essbase Services 11.1.1 - hypservice_1"
waitfor NONEXISTINGSIGNAL /T 5
REM ------starting Essbase ADM ----------
sc \\machine start "Hyperion Administration Services - Web Application"
waitfor NONEXISTINGSIGNAL /T 5
REM --------starting integration -------
sc \\machine start "Hyperion Integration Services"
waitfor NONEXISTINGSIGNAL /T 5
REM -------Hyperion Provider Services Web application----------------
sc \\machine start HyS9aps
waitfor NONEXISTINGSIGNAL /T 5
REM --------starting workspace-----------------
sc \\machine start "Hyperion Workspace - Web Application"
waitfor NONEXISTINGSIGNAL /T 5
sc \\machine start "Hyperion Workspace - Agent Service"
waitfor NONEXISTINGSIGNAL /T 5
sc \\machine start "Hyperion Annotation Server"
waitfor NONEXISTINGSIGNAL /T 5
REM -------------starting Planning-------
sc \\machine start "Hyperion Planning - Web Application"
waitfor NONEXISTINGSIGNAL /T 10
REM --------starting EPMA Core Services-------------
REM ---the next 4 services will be started by Process manager automatically---
REM Hyperion EPM Architect - .Net JNI Bridge
REM Hyperion EPM Architect - Engine Manager
REM Hyperion EPM Architect - Event Manager
REM Hyperion EPM Architect - Job Manager
sc \\machine start "Hyperion EPM Architect - Process Manager"
waitfor NONEXISTINGSIGNAL /T 60
REM --------starting EPMA Architect-------------
sc \\machine start "Hyperion EPM Architect - Web Application"
REM waitfor NONEXISTINGSIGNAL /T 10
sc \\machine start "Hyperion EPM Architect Data Synchronization - Web Application"
REM waitfor NONEXISTINGSIGNAL /T 10
sc \\machine start "Hyperion CALC Manager - Web Application"
REM waitfor NONEXISTINGSIGNAL /T 10
REM -------Hyperion Financial Reporting Java RMI Registry------------------
sc \\machine start HyS9FRRMI
waitfor NONEXISTINGSIGNAL /T 2
REM -------Hyperion Financial Reporting Print Server----------------------------
sc \\machine start HyS9FRPrint
waitfor NONEXISTINGSIGNAL /T 2
REM -------Hyperion Financial Reporting Report Server---------------------------
sc \\machine start HyS9FRReport
waitfor NONEXISTINGSIGNAL /T 2
REM -------Hyperion Financial Reporting Scheduler Server------------------------
sc \\machine start HyS9FRSched
waitfor NONEXISTINGSIGNAL /T 2
REM -------Hyperion Financial Reporting Web application-------------------------
sc \\machine start HyS9FRWeb
waitfor NONEXISTINGSIGNAL /T 5
REM -------starting web analysis ------------------
sc \\machine start "Hyperion Web Analysis - Web Application"
REM waitfor NONEXISTINGSIGNAL /T 5
REM -------Hyperion Workspace Web application(Weblogic is included already---------------------------
REM -------The registry path refers this service to start weblogic -------------------
sc \\machine start HyS9Workspace
waitfor NONEXISTINGSIGNAL /T 20
REM ALL DONE!
waitfor NONEXISTINGSIGNAL /T 30
4/3/10
Cannot start essmsh?
essmsh cannot be started from command line, if this happens, do the next steps:
1.
set path = C:\Hyperion\products\Essbase\EssbaseClient\bin
2. Add C:\Hyperion\products\Essbase\EssbaseClient\bin to the Path environment variable as follows
 3. Restart computer
3. Restart computer
1.
set path = C:\Hyperion\products\Essbase\EssbaseClient\bin
2. Add C:\Hyperion\products\Essbase\EssbaseClient\bin to the Path environment variable as follows

3/30/10
ODI configuration with SQL 2005 server
1. Download Oracle Data Indicator Software from http://edelivery.oracle.com/
2. Check the Windows system, to see if it is 64 bit or 32 bit.
3. Download Java JDK 1.6 the Java JDK is installed C:\Program Files\Java\jdk1.6.0_18
4. Java Environment Variable setting, set ODI_JAVA_HOME = C:\Program Files\Java\jdk1.6.0_18

5. Install the ODI software in Windows system
6. Download Java JDBC driver for SQL Server, sqljdbc_2.0.1803.100_enu.exe, extract it and copy the files to C:\OraHome_1\oracledi\drivers folder
7. Delete the sqljdbc.jar but keep the sqljdbc4.jar file, because the sqljdbc4.jar is the correct driver file for ODI SQL JDBC linksqljdbc4.jar and sqljdbc.jar.
Note:
For JDK5 – use sqljdbc.jar
for JDK6 – use sqljdbc4.jar
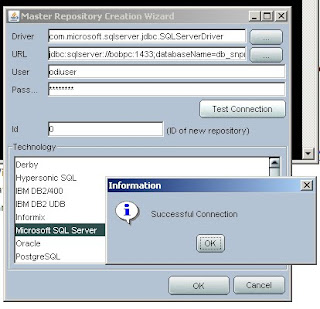
8. Create ODI Master Repository using Repository Management
2. Check the Windows system, to see if it is 64 bit or 32 bit.
3. Download Java JDK 1.6 the Java JDK is installed C:\Program Files\Java\jdk1.6.0_18
4. Java Environment Variable setting, set ODI_JAVA_HOME = C:\Program Files\Java\jdk1.6.0_18

5. Install the ODI software in Windows system
6. Download Java JDBC driver for SQL Server, sqljdbc_2.0.1803.100_enu.exe, extract it and copy the files to C:\OraHome_1\oracledi\drivers folder
7. Delete the sqljdbc.jar but keep the sqljdbc4.jar file, because the sqljdbc4.jar is the correct driver file for ODI SQL JDBC linksqljdbc4.jar and sqljdbc.jar.
Note:
For JDK5 – use sqljdbc.jar
for JDK6 – use sqljdbc4.jar
8. Create ODI Master Repository using Repository Management

3/18/10
SQL Server file system backup and recovery method
1. ntbackup command to backup the SQL file system
2. reg command to backup the windows registry
Important: when we recover file system from file system backup, first DELETE the files that have been damaged or maybe damaged, otherwise, the existing file will NOT be recoverred from the backup, this is very important!
Example: Suppose, the SQL Master database is damaged, and the SQL server cannot be started. Here is the steps: Open the C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data folder, for all of the files that have new time stamps after the existing backup time, move them to a temp folder, or simply delete all of the files in C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data folder. This will force a clean recovery. And then,use ntbackup command line to recover the C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data folder from the backup.
-----------
Below is the script for backup the SQL file systems:
@ECHO OFF
REM --------------------------------------------------------------------------------
REM Procedure Name: BackupSQLFileSystem.bat
REM Created By: Bob Wang
REM Creation Date: 17-Mar-2010
REM Functionality: 1. backup SQL File System
REM 2. backup hKEY_LOCAL_MACHINE registries
REM
REM Modification History:
REM ---------------------------------------------------------------------------------
@for /f "Tokens=1-4 Delims=/ " %%i in ('date /t') do @set dt=%%i-%%j-%%k-%%l
@for /f "Tokens=1" %%i in ('time /t') do @set tm=-%%i
@set tm=%tm::=-%
@set dtt=%dt%%tm%
@echo SQL file system full backup set: %dtt%.
@echo Please wait...
@C:\WINDOWS\system32\ntbackup.exe backup "@C:\download\GoLive\SQL Server\set_SQL.bks" /a /d "Backup %dtt%" /v:no /r:no /rs:no /hc:off /m copy /j "%dtt%" /l:s /f "C:\SQL Server Backup\SQLFileSystemBackup %dtt%.bkf"
@ECHO eXPORT HKEY_LOCAL_MACHINE registries ..
@C:\WINDOWS\system32\REG.exe EXPORT HKLM "C:\SQL Server Backup\HKEY_LOCAL_MACHINE_Backup %dtt%.reg"
-----------------------------
The improved code:
@ECHO OFF
REM --------------------------------------------------------------------------------
REM Procedure Name: BackupSQLFileSystem.bat
REM Created By: Bob Wang
REM Creation Date: 17-Mar-2010
REM Functionality: 1. backup SQL File System
REM 2. backup hKEY_LOCAL_MACHINE registries
REM
REM Modification History:
REM ---------------------------------------------------------------------------------
@set path1="C:\WINDOWS\system32\ntbackup.exe"
@set path2="@C:\download\GoLive\SQL Server\set_SQL.bks"
@set path3="C:\SQL Server Backup\SQLFileSystemBackup %dtt%.bkf"
@set path4="C:\SQL Server Backup\HKEY_LOCAL_MACHINE_Backup %dtt%.reg"
@for /f "Tokens=1-4 Delims=/ " %%i in ('date /t') do @set dt=%%i-%%j-%%k-%%l
@for /f "Tokens=1" %%i in ('time /t') do @set tm=-%%i
@set tm=%tm::=-%
@set dtt=%dt%%tm%
@echo SQL file system full backup set: %dtt%.
@echo Please wait...
@%path1% backup %path2% /a /d "Backup %dtt%" /v:no /r:no /rs:no /hc:off /m copy /j "%dtt%" /l:s /f %path3%
@ECHO eXPORT HKEY_LOCAL_MACHINE registries ..
@C:\WINDOWS\system32\REG.exe EXPORT HKLM %path4%
2. reg command to backup the windows registry
Important: when we recover file system from file system backup, first DELETE the files that have been damaged or maybe damaged, otherwise, the existing file will NOT be recoverred from the backup, this is very important!
Example: Suppose, the SQL Master database is damaged, and the SQL server cannot be started. Here is the steps: Open the C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data folder, for all of the files that have new time stamps after the existing backup time, move them to a temp folder, or simply delete all of the files in C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data folder. This will force a clean recovery. And then,use ntbackup command line to recover the C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\Data folder from the backup.
-----------
Below is the script for backup the SQL file systems:
@ECHO OFF
REM --------------------------------------------------------------------------------
REM Procedure Name: BackupSQLFileSystem.bat
REM Created By: Bob Wang
REM Creation Date: 17-Mar-2010
REM Functionality: 1. backup SQL File System
REM 2. backup hKEY_LOCAL_MACHINE registries
REM
REM Modification History:
REM ---------------------------------------------------------------------------------
@for /f "Tokens=1-4 Delims=/ " %%i in ('date /t') do @set dt=%%i-%%j-%%k-%%l
@for /f "Tokens=1" %%i in ('time /t') do @set tm=-%%i
@set tm=%tm::=-%
@set dtt=%dt%%tm%
@echo SQL file system full backup set: %dtt%.
@echo Please wait...
@C:\WINDOWS\system32\ntbackup.exe backup "@C:\download\GoLive\SQL Server\set_SQL.bks" /a /d "Backup %dtt%" /v:no /r:no /rs:no /hc:off /m copy /j "%dtt%" /l:s /f "C:\SQL Server Backup\SQLFileSystemBackup %dtt%.bkf"
@ECHO eXPORT HKEY_LOCAL_MACHINE registries ..
@C:\WINDOWS\system32\REG.exe EXPORT HKLM "C:\SQL Server Backup\HKEY_LOCAL_MACHINE_Backup %dtt%.reg"
-----------------------------
The improved code:
@ECHO OFF
REM --------------------------------------------------------------------------------
REM Procedure Name: BackupSQLFileSystem.bat
REM Created By: Bob Wang
REM Creation Date: 17-Mar-2010
REM Functionality: 1. backup SQL File System
REM 2. backup hKEY_LOCAL_MACHINE registries
REM
REM Modification History:
REM ---------------------------------------------------------------------------------
@set path1="C:\WINDOWS\system32\ntbackup.exe"
@set path2="@C:\download\GoLive\SQL Server\set_SQL.bks"
@set path3="C:\SQL Server Backup\SQLFileSystemBackup %dtt%.bkf"
@set path4="C:\SQL Server Backup\HKEY_LOCAL_MACHINE_Backup %dtt%.reg"
@for /f "Tokens=1-4 Delims=/ " %%i in ('date /t') do @set dt=%%i-%%j-%%k-%%l
@for /f "Tokens=1" %%i in ('time /t') do @set tm=-%%i
@set tm=%tm::=-%
@set dtt=%dt%%tm%
@echo SQL file system full backup set: %dtt%.
@echo Please wait...
@%path1% backup %path2% /a /d "Backup %dtt%" /v:no /r:no /rs:no /hc:off /m copy /j "%dtt%" /l:s /f %path3%
@ECHO eXPORT HKEY_LOCAL_MACHINE registries ..
@C:\WINDOWS\system32\REG.exe EXPORT HKLM %path4%
SQL backup Script
DECLARE @name VARCHAR(50) -- database name
DECLARE @path VARCHAR(256) -- path for backup files
DECLARE @fileName VARCHAR(256) -- filename for backup
DECLARE @fileDate VARCHAR(20) -- used for file name
SET @path = 'C:\Backup\'
SELECT @fileDate = CONVERT(VARCHAR(20),GETDATE(),112)
DECLARE db_cursor CURSOR FOR
SELECT name
FROM master.dbo.sysdatabases
WHERE name NOT IN ('master','model','msdb','tempdb')
OPEN db_cursor
FETCH NEXT FROM db_cursor INTO @name
WHILE @@FETCH_STATUS = 0
BEGIN
SET @fileName = @path + @name + '_' + @fileDate + '.BAK'
BACKUP DATABASE @name TO DISK = @fileName
FETCH NEXT FROM db_cursor INTO @name
END
CLOSE db_cursor
DEALLOCATE db_cursor
DECLARE @path VARCHAR(256) -- path for backup files
DECLARE @fileName VARCHAR(256) -- filename for backup
DECLARE @fileDate VARCHAR(20) -- used for file name
SET @path = 'C:\Backup\'
SELECT @fileDate = CONVERT(VARCHAR(20),GETDATE(),112)
DECLARE db_cursor CURSOR FOR
SELECT name
FROM master.dbo.sysdatabases
WHERE name NOT IN ('master','model','msdb','tempdb')
OPEN db_cursor
FETCH NEXT FROM db_cursor INTO @name
WHILE @@FETCH_STATUS = 0
BEGIN
SET @fileName = @path + @name + '_' + @fileDate + '.BAK'
BACKUP DATABASE @name TO DISK = @fileName
FETCH NEXT FROM db_cursor INTO @name
END
CLOSE db_cursor
DEALLOCATE db_cursor
3/16/10
Map IP address to Host Name
You can ping the server IP address, but cannot ping the host name of the server.
Solution: add record in the client host file. The host file is located at \windows\system32\drivers\etc\*
----------------
Detail:
You are having a Name Resolution issue. The internet uses a DNS service to
map names to ip-addresses. However, those are Public ip-addresses, not private
Lan addresses. To solve this Windows uses multiple techniques:
a Master Browser to record systems
the host file
If you have dependable ip-addresses (ie: static addresses or MAC enforced ip assignments),
then you can enter the mapping into your host file (this is the technique I use).
The host file is located at \windows\system32\drivers\etc\* and the format of the entry is
ip-address (one or more spaces) theSystemName
The host file allows any system to be included, private (eg your desktop) and public
(eg www.google.com) -- but make sure you get the ip-address correct!
Solution: add record in the client host file. The host file is located at \windows\system32\drivers\etc\*
----------------
Detail:
You are having a Name Resolution issue. The internet uses a DNS service to
map names to ip-addresses. However, those are Public ip-addresses, not private
Lan addresses. To solve this Windows uses multiple techniques:
a Master Browser to record systems
the host file
If you have dependable ip-addresses (ie: static addresses or MAC enforced ip assignments),
then you can enter the mapping into your host file (this is the technique I use).
The host file is located at \windows\system32\drivers\etc\* and the format of the entry is
ip-address (one or more spaces) theSystemName
The host file allows any system to be included, private (eg your desktop) and public
(eg www.google.com) -- but make sure you get the ip-address correct!
Apachy Web Server Plug-in folder
In the process of configuration, the environment is: SQL 2005, Windows 2003, the installed component is: Weblogic 9.2, EPMA, Essbase, Planning, SmartView. when I configure the web server, I select Apachy, and the next screen ask for the web server plug in folder, "Enter the directory where the plug-ins(mod_wl_20.so) are installed".
There are 2 ways to find the directory:
Way One:
1. Download and apply the web server plug-in patch #7825156 from OracleMetaLink as per the instructions below:
• Select the Patches and Updates tab after logging in to OracleMetaLink.
• Click Simple Search.
• In the Search By field, select Patch Number from the list.
• Enter the patch number. The patch number may be different for different product releases and platforms.
• Select the platform (or choose generic as applicable)
• Click Go.
• Click Download to download the patch.
Way Two:
When installed weblogic, select custom install and select "web server plugins", this will install the files you need in the BEA installation.
There are 2 ways to find the directory:
Way One:
1. Download and apply the web server plug-in patch #7825156 from OracleMetaLink as per the instructions below:
• Select the Patches and Updates tab after logging in to OracleMetaLink.
• Click Simple Search.
• In the Search By field, select Patch Number from the list.
• Enter the patch number. The patch number may be different for different product releases and platforms.
• Select the platform (or choose generic as applicable)
• Click Go.
• Click Download to download the patch.
Way Two:
When installed weblogic, select custom install and select "web server plugins", this will install the files you need in the BEA installation.
3/11/10
Hyperion - Windows Backup List
File System Backup:
Regular file system backups are recommended for these EPM System products:
. Shared Services (cold backup)
. Dashboard Development Services
. Oracle Hyperion EPM Architect, Fusion Edition
. Oracle Hyperion Performance Scorecard, Fusion Edition
. Planning
. Reporting and Analysis
File system items that are commonly backed up:
. Hyperion home directory (to back up all installed products), especially these subdirectories:
. HYPERION_HOME/common/config/9.5.0.0 (to back up the configuration and reconfiguration settings written to the Shared Services Registry)
. For Oracle Enterprise Performance Management Workspace, Fusion Editionmodules,
. EPM Workspace search index files in HYPERION_HOME/common/config/9.5.0.0/wsearch
. HYPERION_HOME/products/specific_product
. HYPERION_HOME/deployments (EPM System Web application deployment subdirectory)
Note: This item applies only to products that require a Web application server.
. Product applications and application data
. In Windows environments:
. Windows registry: HKEY_LOCAL_MACHINE and all of its subkeys
. Windows Environment Varables
----------
Database Backup
l Databases that store EPM System application data
l Shared Services databases:
m Relational database for Shared Services
This database contains Shared Services Registry, which stores most product
configuration settings.
See “Backing Up the Shared Services Relational Database ” on page 17.
m OpenLDAP database, if OpenLDAP is used as the Shared Services Native Directory
m Oracle Internet Directory database if Oracle Internet Directory is used as the Shared
Services Native Directory
See the Oracle Internet Directory documentation (http://download.oracle.com/docs/
cd/B28196_01/idmanage.1014/b15991.pdf).
Preparing These backups are recommended:
m Physical full backup immediately after installation and configuration
m Weekly cold backup with complete backup of files under HYPERION_HOME/
products/Foundation/openLDAP
m Daily hot backups of transaction logs after OpenLDAP checkpoints are run
The transactions logs are in HYPERION_HOME/products/Foundation/openLDAP/
var/openldap-data/log.000000000x. A backup copies the logs to the logfiles
(Windows) or LogFiles (UNIX) subfolder of the backup folder. Examples: (UNIX)
o Windows—Running backup.bat c:/temp/bck copies the logs to c:/temp/
bck/logfiles/log.000000000x.
o UNIX—Running backup.sh c:/temp/bck copies the logs to c:/temp/bck/
LogFiles/log.000000000x.
Regular file system backups are recommended for these EPM System products:
. Shared Services (cold backup)
. Dashboard Development Services
. Oracle Hyperion EPM Architect, Fusion Edition
. Oracle Hyperion Performance Scorecard, Fusion Edition
. Planning
. Reporting and Analysis
File system items that are commonly backed up:
. Hyperion home directory (to back up all installed products), especially these subdirectories:
. HYPERION_HOME/common/config/9.5.0.0 (to back up the configuration and reconfiguration settings written to the Shared Services Registry)
. For Oracle Enterprise Performance Management Workspace, Fusion Editionmodules,
. EPM Workspace search index files in HYPERION_HOME/common/config/9.5.0.0/wsearch
. HYPERION_HOME/products/specific_product
. HYPERION_HOME/deployments (EPM System Web application deployment subdirectory)
Note: This item applies only to products that require a Web application server.
. Product applications and application data
. In Windows environments:
. Windows registry: HKEY_LOCAL_MACHINE and all of its subkeys
. Windows Environment Varables
----------
Database Backup
l Databases that store EPM System application data
l Shared Services databases:
m Relational database for Shared Services
This database contains Shared Services Registry, which stores most product
configuration settings.
See “Backing Up the Shared Services Relational Database ” on page 17.
m OpenLDAP database, if OpenLDAP is used as the Shared Services Native Directory
m Oracle Internet Directory database if Oracle Internet Directory is used as the Shared
Services Native Directory
See the Oracle Internet Directory documentation (http://download.oracle.com/docs/
cd/B28196_01/idmanage.1014/b15991.pdf).
Preparing These backups are recommended:
m Physical full backup immediately after installation and configuration
m Weekly cold backup with complete backup of files under HYPERION_HOME/
products/Foundation/openLDAP
m Daily hot backups of transaction logs after OpenLDAP checkpoints are run
The transactions logs are in HYPERION_HOME/products/Foundation/openLDAP/
var/openldap-data/log.000000000x. A backup copies the logs to the logfiles
(Windows) or LogFiles (UNIX) subfolder of the backup folder. Examples: (UNIX)
o Windows—Running backup.bat c:/temp/bck copies the logs to c:/temp/
bck/logfiles/log.000000000x.
o UNIX—Running backup.sh c:/temp/bck copies the logs to c:/temp/bck/
LogFiles/log.000000000x.
Windows:Export registries using command line
c:\reg export HKLM\Software\7-zip c:\7-zip.reg
This will export the below key for 7-zip:

This will export the below key for 7-zip:

Windows: stop and start services from the command line
net stop
net start
A full list of the exact services is found in the registry (run regedit.exe) under the HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services key.
Alternatively, you can perform the stop and start using the name that is showed in the Services Control Panel applet by putting the name in quotes, i.e.
net stop ""
net start ""
net start
A full list of the exact services is found in the registry (run regedit.exe) under the HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services key.
Alternatively, you can perform the stop and start using the name that is showed in the Services Control Panel applet by putting the name in quotes, i.e.
net stop "
net start "
3/10/10
The powerful NTbackup command line
For Hyperion, we need to make complete cold backup for many important folders, for windows system, the ntbackup command give us a simple but powerful way to make a backup.
-----------------------
A sample NTbackup script, with the current date/time in the filename and backup label:
If you ever tried to automate NTbackup, you probably got it up and running, scheduled every day or week, but then noticed over time that the date and time labels that go on the backup file are the current date/time of when you created the backup set. This useful shell script provides a more intelligent solution by parsing the current date and time and inserting them into the filename and backup label. This makes the backups much easier to identify in the case where you need to restore some files.
The script below makes a full backup (not differential) of the files specified in the backup set.bks. To get the set.bks, in command line, input ntbackup, press enter key, and select backup wizard, make a select as below and saved the file as set.bks.

It doesn't verify the backup, and lastly it sends a copy of the backup file to another computer (just in case), that's what the last 3 lines are for. You can obviously remove this step if you don't want it.
@for /f "Tokens=1-4 Delims=/ " %%i in ('date /t') do @set dt=%%i-%%j-%%k-%%l
@for /f "Tokens=1" %%i in ('time /t') do @set tm=-%%i
@set tm=%tm::=-%
@set dtt=%dt%%tm%
@echo Copying backup set: %dtt%.
@echo Please wait...
@C:\WINDOWS\system32\ntbackup.exe backup "@C:\Documents and Settings\bob\Local Settings\Application Data\Microsoft\Windows NT\NTBackup\data\set.bks" /a /d "Backup %dtt%" /v:no /r:no /rs:no /hc:off /m copy /j "%dtt%" /l:s /f "C:\test\Backup %dtt%.bkf"
@echo Sending backup file to Server2. Please wait...
@echo not used this time: @xcopy "@G:\Auto Backups\Backup %dtt%.bkf" "@\\Server2\Backup_Copy" /Y
-----------------------
A sample NTbackup script, with the current date/time in the filename and backup label:
If you ever tried to automate NTbackup, you probably got it up and running, scheduled every day or week, but then noticed over time that the date and time labels that go on the backup file are the current date/time of when you created the backup set. This useful shell script provides a more intelligent solution by parsing the current date and time and inserting them into the filename and backup label. This makes the backups much easier to identify in the case where you need to restore some files.
The script below makes a full backup (not differential) of the files specified in the backup set.bks. To get the set.bks, in command line, input ntbackup, press enter key, and select backup wizard, make a select as below and saved the file as set.bks.

It doesn't verify the backup, and lastly it sends a copy of the backup file to another computer (just in case), that's what the last 3 lines are for. You can obviously remove this step if you don't want it.
@for /f "Tokens=1-4 Delims=/ " %%i in ('date /t') do @set dt=%%i-%%j-%%k-%%l
@for /f "Tokens=1" %%i in ('time /t') do @set tm=-%%i
@set tm=%tm::=-%
@set dtt=%dt%%tm%
@echo Copying backup set: %dtt%.
@echo Please wait...
@C:\WINDOWS\system32\ntbackup.exe backup "@C:\Documents and Settings\bob\Local Settings\Application Data\Microsoft\Windows NT\NTBackup\data\set.bks" /a /d "Backup %dtt%" /v:no /r:no /rs:no /hc:off /m copy /j "%dtt%" /l:s /f "C:\test\Backup %dtt%.bkf"
@echo Sending backup file to Server2. Please wait...
@echo not used this time: @xcopy "@G:\Auto Backups\Backup %dtt%.bkf" "@\\Server2\Backup_Copy" /Y
3/4/10
EPMA compare to Classic Planning
The comparison between EPMA and Classic Planning method:
1) The architecture difference between EPMA and Classic:
For Classic Planning applications, databases are created and maintained within Planning. For Performance Management Architect applications, applications are created in Performance Management Architect and deployed to Planning.
2). The advantages of EPMA over Classic in the next case:
If there are many application and we want to centrally develop everything, EPMA is bettter. Besides, EPMA application can use the existing dimensions and template, and easier to develop a new application, the dimension library makes the dimension reusable. EPMA is easier to manage hierarchies through an advanced gui compared to classic, we can share dimensions across not just planning applications but HFM.
3). The great difference in data loading performance
For classic planning, we can use ODI and outline loader for data transferring. The outline loader and ODI utility uses much of the core engine, the data loading is very fast. ODI does not work directly with EPMA and the current adaptors are aimed at classic planning. EPMA may improve over time but now it is not efficient for data loading and very slow. For example, to load a dimension with about 1000 members, EMPA may use 1-3 hours while outline loader and ODI may just use 10 mins only.
4). Calculation Manager and Business Rule Module:
Calculation Manager can only works with EPMA in the olde Hyperion versions, and that used to be a reason to select EPMA. Calculation Manager is more convenient in building the business rules than the business rule module. In version 11.1.1.3, hyperion product is improved, and classic planning can also use Calculation Manager as an important method to create the business rule.
5. The compatibility with ODI:
ODI does not work directly with EPMA and the current adaptors are aimed at classic planning. We can transfer data with ODI to Essbase(the Essbase have the Planning Data) directly using Essbase Adaptor, and don't have to use planning adaptor.
6. Shared Service:
EPMA and classic planning both works with Shared Service.
7. Migration From Classic to EPMA is simple:
It is simple to migrate from classic planning to EPMA planning, there is existing method to migrate Classic Planning Application to EPMA. This give us a choice for the future, because the hyperion product is in improvement, the current defects for EPMA may be solved in the later versions. And the client company may also have a business reason to use EPMA in the future.
1) The architecture difference between EPMA and Classic:
For Classic Planning applications, databases are created and maintained within Planning. For Performance Management Architect applications, applications are created in Performance Management Architect and deployed to Planning.
2). The advantages of EPMA over Classic in the next case:
If there are many application and we want to centrally develop everything, EPMA is bettter. Besides, EPMA application can use the existing dimensions and template, and easier to develop a new application, the dimension library makes the dimension reusable. EPMA is easier to manage hierarchies through an advanced gui compared to classic, we can share dimensions across not just planning applications but HFM.
3). The great difference in data loading performance
For classic planning, we can use ODI and outline loader for data transferring. The outline loader and ODI utility uses much of the core engine, the data loading is very fast. ODI does not work directly with EPMA and the current adaptors are aimed at classic planning. EPMA may improve over time but now it is not efficient for data loading and very slow. For example, to load a dimension with about 1000 members, EMPA may use 1-3 hours while outline loader and ODI may just use 10 mins only.
4). Calculation Manager and Business Rule Module:
Calculation Manager can only works with EPMA in the olde Hyperion versions, and that used to be a reason to select EPMA. Calculation Manager is more convenient in building the business rules than the business rule module. In version 11.1.1.3, hyperion product is improved, and classic planning can also use Calculation Manager as an important method to create the business rule.
5. The compatibility with ODI:
ODI does not work directly with EPMA and the current adaptors are aimed at classic planning. We can transfer data with ODI to Essbase(the Essbase have the Planning Data) directly using Essbase Adaptor, and don't have to use planning adaptor.
6. Shared Service:
EPMA and classic planning both works with Shared Service.
7. Migration From Classic to EPMA is simple:
It is simple to migrate from classic planning to EPMA planning, there is existing method to migrate Classic Planning Application to EPMA. This give us a choice for the future, because the hyperion product is in improvement, the current defects for EPMA may be solved in the later versions. And the client company may also have a business reason to use EPMA in the future.
2/28/10
Installing EPM System Products in a Distributed Environment
You typically install EPM System products in a distributed environment. The number of computers you need depends on several factors, including:
l The size of the applications
l The number of users
l The frequency of concurrent use by multiple users
l Any requirements your organization has for high availability
l Your organization's security requirements
EPM System Installer simplifies the task of installing components in a distributed computing environment. You can install, configure, and validate any components you want on any computer.
l The size of the applications
l The number of users
l The frequency of concurrent use by multiple users
l Any requirements your organization has for high availability
l Your organization's security requirements
EPM System Installer simplifies the task of installing components in a distributed computing environment. You can install, configure, and validate any components you want on any computer.
RAM - Hyperion Installation
C:\download\E12825_01\E12825_01\epm.111\epm_install_start_here.pdf
When deploying all EPM System products to Oracle WebLogic Server on one machine, 6
GB of RAM is recommended
When EPM System components will be deployed to Oracle Application Server in a distributed
environment, all of the Oracle Application Server instances must:
l Reside in the same cluster topology
l Use a single instance of the Application Server Control (the Administration OC4J instance)
to manage all the instances in the cluster
l Use a supported Web server to route requests to the J2EE containers (OC4J instances)
When deploying all EPM System products to Oracle WebLogic Server on one machine, 6
GB of RAM is recommended
When EPM System components will be deployed to Oracle Application Server in a distributed
environment, all of the Oracle Application Server instances must:
l Reside in the same cluster topology
l Use a single instance of the Application Server Control (the Administration OC4J instance)
to manage all the instances in the cluster
l Use a supported Web server to route requests to the J2EE containers (OC4J instances)
Prepare Environment for Hyperion Installation
1.Prepare a DB
2.Prepare a Web Application Server
3.Prepare Web Server
4.Prepare Web Browser
2.Prepare a Web Application Server
3.Prepare Web Server
4.Prepare Web Browser
SSL - Secure Socket Layer
Secure Sockets Layer, a protocol developed by Netscape for transmitting private documents via the Internet. SSL uses a cryptographic system that uses two keys to encrypt data − a public key known to everyone and a private or secret key known only to the recipient of the message. Both Netscape Navigator and Internet Explorer support SSL, and many Web sites use the protocol to obtain confidential user information, such as credit card numbers. By convention, URLs that require an SSL connection start with https: instead of http:.
Another protocol for transmitting data securely over the World Wide Web is Secure HTTP (S-HTTP). Whereas SSL creates a secure connection between a client and a server, over which any amount of data can be sent securely, S-HTTP is designed to transmit individual messages securely. SSL and S-HTTP, therefore, can be seen as complementary rather than competing technologies. Both protocols have been approved by the Internet Engineering Task Force (IETF) as a standard.
Another protocol for transmitting data securely over the World Wide Web is Secure HTTP (S-HTTP). Whereas SSL creates a secure connection between a client and a server, over which any amount of data can be sent securely, S-HTTP is designed to transmit individual messages securely. SSL and S-HTTP, therefore, can be seen as complementary rather than competing technologies. Both protocols have been approved by the Internet Engineering Task Force (IETF) as a standard.
2/26/10
Should I use SSL for Hyperion Installation?
I am going to install Hyperion products for a client, should I enable SSL option? If I enable SSL, the confguration become not successful, if I don't enable SSL, the configuration is successful. Should I do something before I enable SSL during installation? Is it very important to enable SSL? If I don't enable SSL, after installation and configuration, will remote people can see and login the workspace without error?
--------------------
SSL is secure-socket-layer. The EPM Security guide mentions the steps to enable this properly. It is not needed to have Hyperion function properly.
--------------------
SSL is secure-socket-layer. The EPM Security guide mentions the steps to enable this properly. It is not needed to have Hyperion function properly.
- It is required if the client wants all communications between the EPM system encrypted.
- It is a more complex configuration to setup SSL. Some companies use load balancers in front of EPM to encrypt all traffic.
John A. Booth
------------------------------------
If I don't enable SSL, after installation and configuration, will remote people can see and login the workspace without error?
------------------------------------
hi,
1. People can login workspace , even if you dont enable SSL.But the point is , its a protocol which provides security for communication over inernet/network
2. Recently we had done upon client interest,of course we ran into few issues.
3. There are docs available for SSL configuration, one can find it here
file name : Oracle Hyperion Enterprise Performance Management System SSL Configuration Guide Release 11.1.1.3
URL : http://download.oracle.com/docs/cd/E12825_01/nav/portal_1.htm
Sandeep Reddy Enti
HCC
http://hyperionconsultancy.com/
1. People can login workspace , even if you dont enable SSL.But the point is , its a protocol which provides security for communication over inernet/network
2. Recently we had done upon client interest,of course we ran into few issues.
3. There are docs available for SSL configuration, one can find it here
file name : Oracle Hyperion Enterprise Performance Management System SSL Configuration Guide Release 11.1.1.3
URL : http://download.oracle.com/docs/cd/E12825_01/nav/portal_1.htm
Sandeep Reddy Enti
HCC
http://hyperionconsultancy.com/
SSL-enable Shared Services
1 Optional: If the CA root certificate you are using is not from a default trusted third-party CA, import the CA root certificate into the cacerts of the JVM. cacerts is in the /lib/security directory within the JRE install directory.
Ensure that you load the CA root certificate into all JREs used by EPM System (application server,EPM System applications, HTTP servers, LDAP servers, etc.). The typical location of the JVM:
l Oracle Application Server: ORACLE_AS_HOME/jdk/jre/lib/security
l WebLogic (you must import CA root certificate into both jRockit and SUN JVMs):
. jRockit: BEA_HOME/jrockitversion_number/jre/lib/security/cacerts
. SUN: BEA_HOME/jdkversion_number/jre/lib/security/cacerts
where version_number identifies the JRE version.
---------------------
To SSL-enable Shared Services on WebLogic:
1 Log on to WebLogic Administration Console.
2 Select Servers > Shared Services (admin).
3 From General, select SSL Listen Port Enabled.
4 Specify the port (for example, 28083) on which Shared Services listens for SSL communication.
5 From Keystore, set up the identity and trust keystore.
If you are not using a root certificate from a trusted third-party CA, verify that your root CA certificate is loaded into the trust keystore and that the server certificate is loaded into your identity keystore.
6 From SSL, set up the key alias, certificate location, and pass phrase.
7 Optional: Click Advanced and set Hostname Verification value to None.
Ensure that you load the CA root certificate into all JREs used by EPM System (application server,EPM System applications, HTTP servers, LDAP servers, etc.). The typical location of the JVM:
l Oracle Application Server: ORACLE_AS_HOME/jdk/jre/lib/security
l WebLogic (you must import CA root certificate into both jRockit and SUN JVMs):
. jRockit: BEA_HOME/jrockitversion_number/jre/lib/security/cacerts
. SUN: BEA_HOME/jdkversion_number/jre/lib/security/cacerts
where version_number identifies the JRE version.
---------------------
To SSL-enable Shared Services on WebLogic:
1 Log on to WebLogic Administration Console.
2 Select Servers > Shared Services (admin).
3 From General, select SSL Listen Port Enabled.
4 Specify the port (for example, 28083) on which Shared Services listens for SSL communication.
5 From Keystore, set up the identity and trust keystore.
If you are not using a root certificate from a trusted third-party CA, verify that your root CA certificate is loaded into the trust keystore and that the server certificate is loaded into your identity keystore.
6 From SSL, set up the key alias, certificate location, and pass phrase.
7 Optional: Click Advanced and set Hostname Verification value to None.
Obtaining and Using Certificates from a CA
Obtaining a certificate from a CA typically involves the following actions:
l Generating a certificate request and sending it to the CA for processing.
l Receiving the digitally signed certificate from the CA.
If the JRE is configured to use your own trusted keystore (and not the default trusted store cacerts), you must load the CA root certificate into your trusted keystore and not into the default trusted store cacerts. To determine whether your JRE is using your own trusted keystore, ensure that the javax.net.ssl.trustStore Java start parameter points to trusted keystore; for example, -
Djavax.net.ssl.trustStore=Absolute_path_to_Trusted_keystore
l Generating a certificate request and sending it to the CA for processing.
l Receiving the digitally signed certificate from the CA.
If the JRE is configured to use your own trusted keystore (and not the default trusted store cacerts), you must load the CA root certificate into your trusted keystore and not into the default trusted store cacerts. To determine whether your JRE is using your own trusted keystore, ensure that the javax.net.ssl.trustStore Java start parameter points to trusted keystore; for example, -
Djavax.net.ssl.trustStore=Absolute_path_to_Trusted_keystore
SSL - Hyperion Installation
You have determined the deployment topology and identified the communication links that are to be secured using SSL. Note that if you SSL-enable the Web server, you must also SSLenable the application server. EPM System products do not support SSL offloading.
You have obtained the required certificates from a Certificate Authority (CA), either a wellknown CA or your own, or created self-signed certificates. You must obtain certificates for Web server, application server, and user directories. Each server that hosts EPM System products requires a separate certificate.
You have obtained the required certificates from a Certificate Authority (CA), either a wellknown CA or your own, or created self-signed certificates. You must obtain certificates for Web server, application server, and user directories. Each server that hosts EPM System products requires a separate certificate.
2/25/10
configure EPM System products
Only 32-bit application servers are supported for auto-deployment.
Choose a method to launch EPM System Configurator:
l On the last page of EPM System Installer, click Configure.
l From the Start menu, select Programs, then Oracle EPM System, then Foundation Services, and then EPM System Configurator.
l Double-click configtool.bat from HYPERION_HOME/common/config/ version_number.
l From a Windows console, change to HYPERION_HOME/common/config/version_number, and then enter startconfigtool.bat -console.
l Create a silent configuration response file. See “Performing Silent Configurations” on page 108.
l On UNIX, change to HYPERION_HOME/common/config/version_number and then type ./configtool.sh.
l On UNIX, change to HYPERION_HOME/common/config/version_number and then type ./configtool.sh —console
Choose a method to launch EPM System Configurator:
l On the last page of EPM System Installer, click Configure.
l From the Start menu, select Programs, then Oracle EPM System, then Foundation Services, and then EPM System Configurator.
l Double-click configtool.bat from HYPERION_HOME/common/config/ version_number.
l From a Windows console, change to HYPERION_HOME/common/config/version_number, and then enter startconfigtool.bat -console.
l Create a silent configuration response file. See “Performing Silent Configurations” on page 108.
l On UNIX, change to HYPERION_HOME/common/config/version_number and then type ./configtool.sh.
l On UNIX, change to HYPERION_HOME/common/config/version_number and then type ./configtool.sh —console
Configuring Products in an SSL-Enabled Environment
If you are configuring EPM System products for SSL, configure in this order:
1. Configure Shared Services first. To configure Shared Services, select the Foundation tasks on the Product Selection page of EPM System Configurator: “Common Settings,” “Configure Database,” “Deploy to Application Server.” On the “Common Settings” page, select “Enable SSL for communications.”
2. Set up Shared Services for SSL.
See Oracle Hyperion Enterprise Performance Management System SSL Configuration Guide.
3. Make sure Shared Services is running.
4. Configure the rest of the EPM System products.
5. Set up other EPM System products for SSL.
See Oracle Hyperion Enterprise Performance Management System SSL Configuration Guide.
1. Configure Shared Services first. To configure Shared Services, select the Foundation tasks on the Product Selection page of EPM System Configurator: “Common Settings,” “Configure Database,” “Deploy to Application Server.” On the “Common Settings” page, select “Enable SSL for communications.”
2. Set up Shared Services for SSL.
See Oracle Hyperion Enterprise Performance Management System SSL Configuration Guide.
3. Make sure Shared Services is running.
4. Configure the rest of the EPM System products.
5. Set up other EPM System products for SSL.
See Oracle Hyperion Enterprise Performance Management System SSL Configuration Guide.
Prepare a DB - Hyperion Installation Preparation
Before you install and configure most EPM System products, you must create a database using a supported RDBMS (Oracle Database, Microsoft SQL Server, or IBM DB2). For ease of deployment and simplicity, you can use one database repository for all products (with the exceptions noted below). When you configure multiple products at one time using Oracle's Hyperion Enterprise Performance Management System Configurator, one database is configured for all selected products.
Caution! To use a different database for each product, perform the “Configure Database” task separately for each product. In some cases you might want to configure separate databases for products. Consider performance, roll-back procedures for a single application or product, and disaster recovery plans.
The following products and product components require unique databases:
For information about the FDM database, see the Oracle Hyperion Financial Data Quality Management DBA Guide.
The following products and product components require unique databases:
- Performance Management Architect interface data source.
- Extended Analytics for Financial Management and Extended Analytics for Strategic Finance.
- Planning. Each Planning application should have its own repository.
- Performance Scorecard.
- FDM. Use an Oracle Database instance exclusively for FDM.
- Data Relationship Management. See the Oracle Hyperion Data Relationship Management Installation Guide.
AIX - Hyperion Installation Preparation
Prepare the Production Reporting Server:
A C compiler is required to relink the Production Reporting Server executables for all platforms except
Sun Solaris. For the AIX platform, a C++ compiler is required. If you need an installed C++ compiler, you can download the required C++ components from the following locations.
For AIX, go to:
http://www-1.ibm.com/support/docview.wss?uid=swg24001174
No changes to the Production Reporting Server linking scripts are required.
-----------------
Prepare the runtime environment on AIX:
Interactive Reporting, Financial Reporting, Web Analysis, and in some cases Essbase Server require an updated C++ runtime environment version on AIX 5L.
To obtain the update:
A C compiler is required to relink the Production Reporting Server executables for all platforms except
Sun Solaris. For the AIX platform, a C++ compiler is required. If you need an installed C++ compiler, you can download the required C++ components from the following locations.
http://www-1.ibm.com/support/docview.wss?uid=swg24001174
No changes to the Production Reporting Server linking scripts are required.
-----------------
Prepare the runtime environment on AIX:
Interactive Reporting, Financial Reporting, Web Analysis, and in some cases Essbase Server require an updated C++ runtime environment version on AIX 5L.
To obtain the update:
- Go to the IBM technical support website (https://techsupport.services.ibm.com/.)
- Search for the PTF number (U489780) or the fileset (xlC.aix50.rte.6.0.0.7) and download the file
SSL and WebServer - Hyperion Installation
For automatic deployment, the Web server must reside on the same machine where EPM Workspace will be deployed.
If you are using secure communication, ensure availability of SSL certificates for all components.
Ensure that Web application servers are available for EPM System product deployment. The application server and the product that you are deploying must be installed on the same computer. Web server should be installed BEFROE you install the Hyperion products.
EPM Workspace and the application being integrated must be deployed to the same Web application server type. For example, if EPM Workspace is deployed to Oracle WebLogic Server, Performance Management Architect must also be deployed to WebLogic Server.
If you are using secure communication, ensure availability of SSL certificates for all components.
Ensure that Web application servers are available for EPM System product deployment. The application server and the product that you are deploying must be installed on the same computer. Web server should be installed BEFROE you install the Hyperion products.
EPM Workspace and the application being integrated must be deployed to the same Web application server type. For example, if EPM Workspace is deployed to Oracle WebLogic Server, Performance Management Architect must also be deployed to WebLogic Server.
Resolve potential firewall - Hyperion Installation Preparation
For example, in some cases, Essbase Integration Services Console is used on a client computer that is outside the network firewall, and the console requires access to Integration Server and Essbase Server, which are located inside the network firewall. In these cases, you must log on to Essbase Server with a name that both the client system and Integration Server can use to communicate with Essbase Server.
Problems arise when you attempt to log on using the external IP address of the computer running Essbase Server. Integration Server cannot use the external IP address to communicate with the computer running Essbase Server because both Essbase Server and Integration Server are inside the firewall. Administrators can solve this problem by defining an alias for the Essbase Server computer that is usable from both sides of the firewall.
Problems arise when you attempt to log on using the external IP address of the computer running Essbase Server. Integration Server cannot use the external IP address to communicate with the computer running Essbase Server because both Essbase Server and Integration Server are inside the firewall. Administrators can solve this problem by defining an alias for the Essbase Server computer that is usable from both sides of the firewall.
UNIX - Hyperion Products Installation Preparation
l For UNIX systems, create a login to install, configure, and run EPM System products. The account that is used to install EPM System products must have Read, Write, and Execute permissions on $HYPERION_HOME.
Oracle recommends that you do not install, configure, and run EPM System products using the root user.
Oracle recommends that you do not install, configure, and run EPM System products using the root user.
- For each UNIX server, prepare a user account (not the root). Install and configure as the same user for all EPM System products.
- If you are using Oracle Application Server, you must install and configure EPM System products using the same user you used to install Oracle Application Server.
- If you have installed any other Oracle products, the user that will be installing EPM System products must be part of the same group as the user who installed the other Oracle products. For example, both users must be part of oinstall. If you are upgrading EPM System products, follow this requirement even if you used multiple users to install components in previous releases.
2/24/10
WebLogic cluster
A WebLogic cluster is a collection of WebLogic Server instances that work together to provide a reliable, scalable environment for your applications. WebLogic Server clusters increase reliability by supporting failover; WebLogic automatically switchs requests and processing to a redundant server upon the failure or abnormal termination of the currently-active server. A WebLogic cluster always contains one Administration Server that handles all the administrative duties like, for example, deploying applications and configuring your cluster. You do not deploy applications on the Administration Server, you deploy applications to the Managed Servers that make up the cluster.
Troubleshooting:
Your cluster should not share its multicast port with other applications on your network. If it does, conflicts can result, and you will have problems starting Managed Servers in the cluster, binding objects to the cluster wide JNDI tree, and deploying applications to the cluster. An error like the following in your managed server log is due to a conflicting multicast port/address.
Troubleshooting:
Your cluster should not share its multicast port with other applications on your network. If it does, conflicts can result, and you will have problems starting Managed Servers in the cluster, binding objects to the cluster wide JNDI tree, and deploying applications to the cluster. An error like the following in your managed server log is due to a conflicting multicast port/address.
2/14/10
ODI Installation Problem - JDK
After installation the ODI, to run a package in command line, the JDK should be installed.
1. Download JDK from sun website, after installation, for windows, you will find the next folder: C:\Program Files\Java\jdk1.6.0_18
2. Set environment variable:
set ODI_JAVA_HOME =C:\Program Files\Java\jdk1.6.0_18
This seeting will overwrite the default setting. jdk will replace jre
3. For UNIX, the setting is similar, but beed to be very careful to give the WRITE pomission for the related directories.
1. Download JDK from sun website, after installation, for windows, you will find the next folder: C:\Program Files\Java\jdk1.6.0_18
2. Set environment variable:
set ODI_JAVA_HOME =C:\Program Files\Java\jdk1.6.0_18
This seeting will overwrite the default setting. jdk will replace jre
3. For UNIX, the setting is similar, but beed to be very careful to give the WRITE pomission for the related directories.
Oracle Data Indicator - ODI
Oracle Data Integrator employs a powerful declarative design approach to ETL, which separates the declarative rules from the implementation details. Oracle Data Integrator is also based on a unique “E-LT” architecture which eliminates the need for a standalone ETL server and proprietary engine, and instead leverages the inherent power of your RDBMS engines. This combination provides the greatest productivity for both development and maintenance, and the highest performance for the execution of data transformation and validation processes.
Here are the key reasons why more than 500 companies have chosen Oracle Data Integrator for their ETL needs:
• Faster and simpler development and maintenance: The declarative rules driven approach to ETL greatly reduces the learning curve of the product and increases developer productivity while facilitating ongoing maintenance. This approach separates the definition of the processes from their actual implementation, and separates the declarative rules (the “what”) from the data flows (the “how”).
• Data quality firewall: Oracle Data Integrator ensures that faulty data is automatically detected and recycled before insertion in the target application. This is performed without the need for programming, following the data integrity rules and constraints defined both on the target application and in Oracle Data Integrator.
• Better execution performance: traditional ETL software is based on proprietary engines that perform data transformations row by row, thus limiting performance. By implementing an E-LT architecture, based on your existing RDBMS engines and SQL, you are capable of executing data transformations on the target server at a set-based level, giving you much higher performance.
• Simpler and more efficient architecture: the E-LT architecture removes the need for an ETL hub server sitting between the sources and the target server. It utilizes the target server and its RDBMS to perform complex transformations, most of which happen in batch mode when the server is not busy processing end-user queries.
• Platform Independence: Oracle Data Integrator supports all platforms, hardware and OSs with the same software.
• Data Connectivity: Oracle Data Integrator supports all RDBMSs including all leading Data Warehousing platforms such as Teradata, IBM DB2, Netezza, Oracle, Sybase IQ and numerous other technologies such as flat files, ERPs, LDAP, XML.
• Cost-savings: the elimination of the ETL hub server and ETL engine reduces both the initial hardware and software acquisition and maintenance costs. The reduced learning curve and increased developer productivity significantly reduce the overall labor costs of the project, as well as the cost of ongoing enhancements.
Here are the key reasons why more than 500 companies have chosen Oracle Data Integrator for their ETL needs:
• Faster and simpler development and maintenance: The declarative rules driven approach to ETL greatly reduces the learning curve of the product and increases developer productivity while facilitating ongoing maintenance. This approach separates the definition of the processes from their actual implementation, and separates the declarative rules (the “what”) from the data flows (the “how”).
• Data quality firewall: Oracle Data Integrator ensures that faulty data is automatically detected and recycled before insertion in the target application. This is performed without the need for programming, following the data integrity rules and constraints defined both on the target application and in Oracle Data Integrator.
• Better execution performance: traditional ETL software is based on proprietary engines that perform data transformations row by row, thus limiting performance. By implementing an E-LT architecture, based on your existing RDBMS engines and SQL, you are capable of executing data transformations on the target server at a set-based level, giving you much higher performance.
• Simpler and more efficient architecture: the E-LT architecture removes the need for an ETL hub server sitting between the sources and the target server. It utilizes the target server and its RDBMS to perform complex transformations, most of which happen in batch mode when the server is not busy processing end-user queries.
• Platform Independence: Oracle Data Integrator supports all platforms, hardware and OSs with the same software.
• Data Connectivity: Oracle Data Integrator supports all RDBMSs including all leading Data Warehousing platforms such as Teradata, IBM DB2, Netezza, Oracle, Sybase IQ and numerous other technologies such as flat files, ERPs, LDAP, XML.
• Cost-savings: the elimination of the ETL hub server and ETL engine reduces both the initial hardware and software acquisition and maintenance costs. The reduced learning curve and increased developer productivity significantly reduce the overall labor costs of the project, as well as the cost of ongoing enhancements.
2/3/10
MDX - OpeningPeriod,ClosingPeriod,IIF
WITH MEMBER [Measures].[Starting Invemtory] AS
'IIF(IsLeaf([Year].CurrentMember),
[Measures].[Opening Inventory],
([Measures].[Opening Inventory], OpeningPeriod ([Year].Levels(0),[Year].CurrentMember)))'
MEMBER [Measures].[Closing Invemtory] AS
'IIF(IsLeaf([Year].CurrentMember),
[Measures].[Ending Inventory],
([Measures].[Ending Inventory], ClosingPeriod ([Year].Levels(0),[Year].CurrentMember)))'
SELECT
CrossJoin (
{ [100-10] },
{ [Measures].[Starting Invemtory], [Measures].[Closing Invemtory]}
)
ON COLUMNS,
Hierarchize ( [Year].Members,POST )
ON ROWS
FROM Sample.Basic
100-10 100-10
Starting Inventory Closing Inventory
Jan 14587 14039
Feb 14039 13566
Mar 13566 13660
Qtr1 14587 13660
Apr 13660 14172
May 14172 15127
Jun 15127 15580
Qtr2 13660 15580
Jul 15580 14819
Aug 14819 14055
Sep 14055 13424
Qtr3 15580 13424
Oct 13424 13323
Nov 13323 13460
Dec 13460 12915
Qtr4 13424 12915
Year 14587 12915
'IIF(IsLeaf([Year].CurrentMember),
[Measures].[Opening Inventory],
([Measures].[Opening Inventory], OpeningPeriod ([Year].Levels(0),[Year].CurrentMember)))'
MEMBER [Measures].[Closing Invemtory] AS
'IIF(IsLeaf([Year].CurrentMember),
[Measures].[Ending Inventory],
([Measures].[Ending Inventory], ClosingPeriod ([Year].Levels(0),[Year].CurrentMember)))'
SELECT
CrossJoin (
{ [100-10] },
{ [Measures].[Starting Invemtory], [Measures].[Closing Invemtory]}
)
ON COLUMNS,
Hierarchize ( [Year].Members,POST )
ON ROWS
FROM Sample.Basic
100-10 100-10
Starting Inventory Closing Inventory
Jan 14587 14039
Feb 14039 13566
Mar 13566 13660
Qtr1 14587 13660
Apr 13660 14172
May 14172 15127
Jun 15127 15580
Qtr2 13660 15580
Jul 15580 14819
Aug 14819 14055
Sep 14055 13424
Qtr3 15580 13424
Oct 13424 13323
Nov 13323 13460
Dec 13460 12915
Qtr4 13424 12915
Year 14587 12915
1/26/10
Java Frame
package com.essbase.samples.japi;
import java.awt.*;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import javax.swing.*;
import java.sql.*;
import com.essbase.api.base.*;
import com.essbase.api.session.*;
//import com.essbase.api.datasource.IEssCube;
//import com.essbase.api.datasource.IEssOlapFileObject;
import com.essbase.api.datasource.IEssOlapServer;
import com.essbase.api.domain.*;
public class HypFrame extends JFrame {
/**
*
*/
private JTextField tfname = new JTextField();
private JPasswordField tfpass = new JPasswordField();
private static final int FAILURE_CODE = 1;
void buildConstraints(GridBagConstraints gbc, int gx, int gy,
int gw, int gh, int wx, int wy) {
gbc.gridx = gx;
gbc.gridy = gy;
gbc.gridwidth = gw;
gbc.gridheight = gh;
gbc.weightx = wx;
gbc.weighty = wy;
}
void MainFrame()
{
// String title = (args.length == 0 ? "Main Frame" : args[0]);
JFrame frame= new JFrame("title");
//Container content = frame.getContentPane();
JPanel panel=new JPanel();
JTextArea jt= new JTextArea("Welcome Roseindia",15,29);
frame.add(panel);
//content.add(jt);
JScrollPane rightPane = new JScrollPane(jt);
panel.add(rightPane);
GridBagLayout gridbag = new GridBagLayout();
GridBagConstraints constraints = new GridBagConstraints();
buildConstraints(constraints, 0, 0, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn1 = new JButton("button 1");
gridbag.setConstraints(btn1, constraints);
panel.add(btn1);
buildConstraints(constraints, 0, 1, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn2 = new JButton("button 2");
gridbag.setConstraints(btn2, constraints);
panel.add(btn2);
buildConstraints(constraints, 0, 2, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn3 = new JButton("button 3");
gridbag.setConstraints(btn3, constraints);
panel.add(btn3);
buildConstraints(constraints, 1, 0, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn4 = new JButton("button 4");
gridbag.setConstraints(btn4, constraints);
panel.add(btn4);
buildConstraints(constraints, 1, 1, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn5 = new JButton("button 5");
gridbag.setConstraints(btn5, constraints);
panel.add(btn5);
buildConstraints(constraints, 1, 2, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn6 = new JButton("button 6");
gridbag.setConstraints(btn6, constraints);
panel.add(btn6);
frame.setSize(340,380);
frame.setVisible(true);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
}
public static void main(String[] arguments) {
HypFrame frame = new HypFrame();
frame.setVisible(true);
//.show();
}
void connectEssbase(){
int statusCode = 0; // will set this to FAILURE only if err/exception occurs.
IEssbase ess = null;
String s_provider ="http://localhost:13080/aps/JAPI";
String s_olapSvrName="localhost";
try {
// Create JAPI instance.
ess = IEssbase.Home.create(IEssbase.JAPI_VERSION);
// Sign On to the Provider
IEssDomain dom = ess.signOn(tfname.getText(), tfpass.getText(), false, null, s_provider);
IEssOlapServer olapSvr = dom.getOlapServer(s_olapSvrName);
olapSvr.connect();
System.out.println("Connection to Analyic server '" +olapSvr.getName()+ "' was successful.");
String apiVersion = ess.getApiVersion();
String apiVerDetail = ess.getApiVersionDetail();
System.out.println("API Version :"+apiVersion);
System.out.println("API Version Detail :"+apiVerDetail);
} catch (EssException x) {
System.err.println("Error: " + x.getMessage());
statusCode = FAILURE_CODE;
} finally {
// Sign off.
try {
if (ess != null && ess.isSignedOn() == true)
ess.signOff();
} catch (EssException x) {
System.err.println("Error: " + x.getMessage());
}
}
// Set status to failure only if exception occurs and do abnormal termination
// otherwise, it will by default terminate normally
if (statusCode == FAILURE_CODE) System.exit(FAILURE_CODE);
}
void connectOrcl(){
String data = "jdbc:odbc:orcl";
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
Connection conn = DriverManager.getConnection(data,
tfname.getText(), tfpass.getText());
Statement st = conn.createStatement();
System.out.println("Connected to orcl successfully!");
ResultSet rec = st.executeQuery(
"SELECT * " +
"FROM TBC.Family " +
"WHERE " +
"(FAMILYID='" + 1 + "') " +
"ORDER BY FAMILYID");
System.out.println("FIPS\tCOUNTRY\tYEAR\t" +
"ANTHRACITE PRODUCTION");
while(rec.next()) {
System.out.println(rec.getString(1) + "\t"
+ rec.getString(2) + "\t"
+ rec.getString(3) + "\t"
+ rec.getString(4));
}
st.close();
} catch (SQLException s) {
System.out.println("SQL Error: " + s.toString() + " "
+ s.getErrorCode() + " " + s.getSQLState());
} catch (Exception e) {
System.out.println("Error: " + e.toString()
+ e.getMessage());
}
}
public HypFrame() {
super("Username and Password");
setSize(290, 110);
GridBagLayout gridbag = new GridBagLayout();
GridBagConstraints constraints = new GridBagConstraints();
JPanel pane = new JPanel();
pane.setLayout(gridbag);
// Name label
buildConstraints(constraints, 0, 0, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JLabel label1 = new JLabel("Username:", JLabel.LEFT);
gridbag.setConstraints(label1, constraints);
pane.add(label1);
// Name text field
buildConstraints(constraints, 1, 0, 1, 1, 90, 0);
constraints.fill = GridBagConstraints.HORIZONTAL;
// JTextField tfname = new JTextField();
gridbag.setConstraints(tfname, constraints);
pane.add(tfname);
// password label
buildConstraints(constraints, 0, 1, 1, 1, 0, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JLabel label2 = new JLabel("Password:", JLabel.LEFT);
gridbag.setConstraints(label2, constraints);
pane.add(label2);
// password text field
buildConstraints(constraints, 1, 1, 1, 1, 0, 0);
constraints.fill = GridBagConstraints.HORIZONTAL;
tfpass.setEchoChar('*');
gridbag.setConstraints(tfpass, constraints);
pane.add(tfpass);
// OK Button
buildConstraints(constraints, 0, 2, 2, 1, 0, 20);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.CENTER;
JButton btnOk = new JButton("Ok");
gridbag.setConstraints(btnOk, constraints);
btnOk.addActionListener(new ButtonListener());
pane.add(btnOk);
setContentPane(pane);
}
class ButtonListener implements ActionListener {
ButtonListener() {
}
public void actionPerformed(ActionEvent e) {
if (e.getActionCommand().equals("Ok")) {
System.out.println("Button Ok has been clicked");
MainFrame();
connectOrcl();
connectEssbase();
}
}
}
}
import java.awt.*;
import java.awt.event.ActionEvent;
import java.awt.event.ActionListener;
import javax.swing.*;
import java.sql.*;
import com.essbase.api.base.*;
import com.essbase.api.session.*;
//import com.essbase.api.datasource.IEssCube;
//import com.essbase.api.datasource.IEssOlapFileObject;
import com.essbase.api.datasource.IEssOlapServer;
import com.essbase.api.domain.*;
public class HypFrame extends JFrame {
/**
*
*/
private JTextField tfname = new JTextField();
private JPasswordField tfpass = new JPasswordField();
private static final int FAILURE_CODE = 1;
void buildConstraints(GridBagConstraints gbc, int gx, int gy,
int gw, int gh, int wx, int wy) {
gbc.gridx = gx;
gbc.gridy = gy;
gbc.gridwidth = gw;
gbc.gridheight = gh;
gbc.weightx = wx;
gbc.weighty = wy;
}
void MainFrame()
{
// String title = (args.length == 0 ? "Main Frame" : args[0]);
JFrame frame= new JFrame("title");
//Container content = frame.getContentPane();
JPanel panel=new JPanel();
JTextArea jt= new JTextArea("Welcome Roseindia",15,29);
frame.add(panel);
//content.add(jt);
JScrollPane rightPane = new JScrollPane(jt);
panel.add(rightPane);
GridBagLayout gridbag = new GridBagLayout();
GridBagConstraints constraints = new GridBagConstraints();
buildConstraints(constraints, 0, 0, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn1 = new JButton("button 1");
gridbag.setConstraints(btn1, constraints);
panel.add(btn1);
buildConstraints(constraints, 0, 1, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn2 = new JButton("button 2");
gridbag.setConstraints(btn2, constraints);
panel.add(btn2);
buildConstraints(constraints, 0, 2, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn3 = new JButton("button 3");
gridbag.setConstraints(btn3, constraints);
panel.add(btn3);
buildConstraints(constraints, 1, 0, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn4 = new JButton("button 4");
gridbag.setConstraints(btn4, constraints);
panel.add(btn4);
buildConstraints(constraints, 1, 1, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn5 = new JButton("button 5");
gridbag.setConstraints(btn5, constraints);
panel.add(btn5);
buildConstraints(constraints, 1, 2, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JButton btn6 = new JButton("button 6");
gridbag.setConstraints(btn6, constraints);
panel.add(btn6);
frame.setSize(340,380);
frame.setVisible(true);
frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);
}
public static void main(String[] arguments) {
HypFrame frame = new HypFrame();
frame.setVisible(true);
//.show();
}
void connectEssbase(){
int statusCode = 0; // will set this to FAILURE only if err/exception occurs.
IEssbase ess = null;
String s_provider ="http://localhost:13080/aps/JAPI";
String s_olapSvrName="localhost";
try {
// Create JAPI instance.
ess = IEssbase.Home.create(IEssbase.JAPI_VERSION);
// Sign On to the Provider
IEssDomain dom = ess.signOn(tfname.getText(), tfpass.getText(), false, null, s_provider);
IEssOlapServer olapSvr = dom.getOlapServer(s_olapSvrName);
olapSvr.connect();
System.out.println("Connection to Analyic server '" +olapSvr.getName()+ "' was successful.");
String apiVersion = ess.getApiVersion();
String apiVerDetail = ess.getApiVersionDetail();
System.out.println("API Version :"+apiVersion);
System.out.println("API Version Detail :"+apiVerDetail);
} catch (EssException x) {
System.err.println("Error: " + x.getMessage());
statusCode = FAILURE_CODE;
} finally {
// Sign off.
try {
if (ess != null && ess.isSignedOn() == true)
ess.signOff();
} catch (EssException x) {
System.err.println("Error: " + x.getMessage());
}
}
// Set status to failure only if exception occurs and do abnormal termination
// otherwise, it will by default terminate normally
if (statusCode == FAILURE_CODE) System.exit(FAILURE_CODE);
}
void connectOrcl(){
String data = "jdbc:odbc:orcl";
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
Connection conn = DriverManager.getConnection(data,
tfname.getText(), tfpass.getText());
Statement st = conn.createStatement();
System.out.println("Connected to orcl successfully!");
ResultSet rec = st.executeQuery(
"SELECT * " +
"FROM TBC.Family " +
"WHERE " +
"(FAMILYID='" + 1 + "') " +
"ORDER BY FAMILYID");
System.out.println("FIPS\tCOUNTRY\tYEAR\t" +
"ANTHRACITE PRODUCTION");
while(rec.next()) {
System.out.println(rec.getString(1) + "\t"
+ rec.getString(2) + "\t"
+ rec.getString(3) + "\t"
+ rec.getString(4));
}
st.close();
} catch (SQLException s) {
System.out.println("SQL Error: " + s.toString() + " "
+ s.getErrorCode() + " " + s.getSQLState());
} catch (Exception e) {
System.out.println("Error: " + e.toString()
+ e.getMessage());
}
}
public HypFrame() {
super("Username and Password");
setSize(290, 110);
GridBagLayout gridbag = new GridBagLayout();
GridBagConstraints constraints = new GridBagConstraints();
JPanel pane = new JPanel();
pane.setLayout(gridbag);
// Name label
buildConstraints(constraints, 0, 0, 1, 1, 10, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JLabel label1 = new JLabel("Username:", JLabel.LEFT);
gridbag.setConstraints(label1, constraints);
pane.add(label1);
// Name text field
buildConstraints(constraints, 1, 0, 1, 1, 90, 0);
constraints.fill = GridBagConstraints.HORIZONTAL;
// JTextField tfname = new JTextField();
gridbag.setConstraints(tfname, constraints);
pane.add(tfname);
// password label
buildConstraints(constraints, 0, 1, 1, 1, 0, 40);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.EAST;
JLabel label2 = new JLabel("Password:", JLabel.LEFT);
gridbag.setConstraints(label2, constraints);
pane.add(label2);
// password text field
buildConstraints(constraints, 1, 1, 1, 1, 0, 0);
constraints.fill = GridBagConstraints.HORIZONTAL;
tfpass.setEchoChar('*');
gridbag.setConstraints(tfpass, constraints);
pane.add(tfpass);
// OK Button
buildConstraints(constraints, 0, 2, 2, 1, 0, 20);
constraints.fill = GridBagConstraints.NONE;
constraints.anchor = GridBagConstraints.CENTER;
JButton btnOk = new JButton("Ok");
gridbag.setConstraints(btnOk, constraints);
btnOk.addActionListener(new ButtonListener());
pane.add(btnOk);
setContentPane(pane);
}
class ButtonListener implements ActionListener {
ButtonListener() {
}
public void actionPerformed(ActionEvent e) {
if (e.getActionCommand().equals("Ok")) {
System.out.println("Button Ok has been clicked");
MainFrame();
connectOrcl();
connectEssbase();
}
}
}
}
1/24/10
Cannot start Essbase Server?
Problem: Cannot start Essbase Server?
The message is: Fatal Error: invalid item Index in Security File.
I can start the Essbase Service in Windows Service, and it shows "started", one second later, I refresh, it shows not started. I think it is about the Essbase.sec file corrupted, and I have rename essbase.bak to essbase.sec, still not working. I don't have an old backup for the essbase.sec. Should I reinstall Essbase? Please advise,thanks!
----------------
Solution 1(by GlennS):
If the security file is corrupted and you don't have a backup, you do not need to reinstall. You might lose all your security information howver.
First, rename the essbase.sec file
Then open a cmd window and enter Essbase.exe you should have Essbase start in the foreground and be asking for information. Enter the organization name
When it asks for the user, put in the admin id then the admin password. It should start Essbase, but none of the applications will be recognized.
Next start EAS and and right click oin the applications and select create application. One by One enter in the application names that are in the arborpath\Essbase\essbase\server\app folder.
It should re-add the applications.
Recreate any filters you had and if you are running shared services try to resync the users and groups.
--------------
Solution 2(by JohnGoodWin):
Just to add if you are using shared services,
have you tried renaming ESSBASE.BAK_startup to ESSBASE.sec to see if that works.
If that doesn't then ESSBASE.BAK_postUPM to ESSBASE.sec will be the essbase sec file just after essbase was converted to shared services mode.
The message is: Fatal Error: invalid item Index in Security File.
I can start the Essbase Service in Windows Service, and it shows "started", one second later, I refresh, it shows not started. I think it is about the Essbase.sec file corrupted, and I have rename essbase.bak to essbase.sec, still not working. I don't have an old backup for the essbase.sec. Should I reinstall Essbase? Please advise,thanks!
----------------
Solution 1(by GlennS):
If the security file is corrupted and you don't have a backup, you do not need to reinstall. You might lose all your security information howver.
First, rename the essbase.sec file
Then open a cmd window and enter Essbase.exe you should have Essbase start in the foreground and be asking for information. Enter the organization name
When it asks for the user, put in the admin id then the admin password. It should start Essbase, but none of the applications will be recognized.
Next start EAS and and right click oin the applications and select create application. One by One enter in the application names that are in the arborpath\Essbase\essbase\server\app folder.
It should re-add the applications.
Recreate any filters you had and if you are running shared services try to resync the users and groups.
--------------
Solution 2(by JohnGoodWin):
Just to add if you are using shared services,
have you tried renaming ESSBASE.BAK_startup to ESSBASE.sec to see if that works.
If that doesn't then ESSBASE.BAK_postUPM to ESSBASE.sec will be the essbase sec file just after essbase was converted to shared services mode.
1/10/10
What is the main develloping tool for design an Essbase?
Which one of the below or else is the main develloping tool to design an Essbase?
1. Essbase Studio Client Console
2. Essbase Integration Service Console
3. Essbase Administration Service Console
Essbase Stidio exists only in version 11, EAS can be used to modify a cube for sure, but in the beginning status to configure a cube, seems we should use another tool for the design of Essbase Cube. EIS is the tool to develope cube from RLDB. But after Essbase Studio appear, seems Essbase Studio is a more powerful tool to develop a CUBE, but I cannot find the method to create attriibute dimension and the place to associate attribute dimension with standard dimension using Essbase Studio Console?
Which tool is the most powerful to create a CUBE that include: alias, formula, attribute dim ans association, and UDA?
---------------
Answer(By JohnGoodWin):
Create a Hierarchy as usual and add your columns for your attribute dimenion, preview make sure your hierarchy is correct. Edit the hierarchy you want to map the attributes dimension to, add the attribute mapping to the hierarchy. (so attribute member mapped to dimension member)
(remember there needs to be a relational ship between the dimension members to the attribute members in your source)
There is an example of adding the mapping to a hierarchy on page 126 of EAS user guide (Multi-chain Hierarchy with Attribute Dimensions)
In the model select dimension > essbase properties > click the attribute member and then select the attribute settings. (this won't appear until you have correctly added the attribute mapping in the hierarchy set up)
------------------
Answer(By Cameron L):
To be totally pedantic, there are two tools that are missing:
1) EPMA -- Not my cup of tea, but can build a database and it supposedly works in v11, at least sometimes
2) If Business Rules is part of EAS, as is the Essbase calc script writer, you need to throw Calc Manager onto the list
I've never built an Essbase database through EPMA (although I have rapidly run away from EPMA/Planning more than once) but it's doable and apparently some like it. To me it is like liver and onions, but to each his own.
Which tool is the "best", or the main one? A case of horses for courses, I think. The project is going to dictate it, but my preference would be:
SQL driven for drill back and database creation (think ASO apps that need to get recreated) -- Studio if possible
Still SQL driven (I love load rules), prototypes (at least for me), BSO, Planning/BSO, calc scripts/HBRs -- EAS
---------------------
Answer(By Daniel):
EAS of course! EIS and Studio is gear towards ability to build a cube with drill back to a relational source. EAS is focus mainly on the cube itself and thus has all the advantages you described and therefore building things like attribute dimensions with ease.
1. Essbase Studio Client Console
2. Essbase Integration Service Console
3. Essbase Administration Service Console
Essbase Stidio exists only in version 11, EAS can be used to modify a cube for sure, but in the beginning status to configure a cube, seems we should use another tool for the design of Essbase Cube. EIS is the tool to develope cube from RLDB. But after Essbase Studio appear, seems Essbase Studio is a more powerful tool to develop a CUBE, but I cannot find the method to create attriibute dimension and the place to associate attribute dimension with standard dimension using Essbase Studio Console?
Which tool is the most powerful to create a CUBE that include: alias, formula, attribute dim ans association, and UDA?
---------------
Answer(By JohnGoodWin):
Create a Hierarchy as usual and add your columns for your attribute dimenion, preview make sure your hierarchy is correct. Edit the hierarchy you want to map the attributes dimension to, add the attribute mapping to the hierarchy. (so attribute member mapped to dimension member)
(remember there needs to be a relational ship between the dimension members to the attribute members in your source)
There is an example of adding the mapping to a hierarchy on page 126 of EAS user guide (Multi-chain Hierarchy with Attribute Dimensions)
In the model select dimension > essbase properties > click the attribute member and then select the attribute settings. (this won't appear until you have correctly added the attribute mapping in the hierarchy set up)
------------------
Answer(By Cameron L):
To be totally pedantic, there are two tools that are missing:
1) EPMA -- Not my cup of tea, but can build a database and it supposedly works in v11, at least sometimes
2) If Business Rules is part of EAS, as is the Essbase calc script writer, you need to throw Calc Manager onto the list
I've never built an Essbase database through EPMA (although I have rapidly run away from EPMA/Planning more than once) but it's doable and apparently some like it. To me it is like liver and onions, but to each his own.
Which tool is the "best", or the main one? A case of horses for courses, I think. The project is going to dictate it, but my preference would be:
SQL driven for drill back and database creation (think ASO apps that need to get recreated) -- Studio if possible
Still SQL driven (I love load rules), prototypes (at least for me), BSO, Planning/BSO, calc scripts/HBRs -- EAS
---------------------
Answer(By Daniel):
EAS of course! EIS and Studio is gear towards ability to build a cube with drill back to a relational source. EAS is focus mainly on the cube itself and thus has all the advantages you described and therefore building things like attribute dimensions with ease.
1/7/10
Change the Database Name in Essbase Studio
Is there a way to change the database name in Essbase Studio, what I can see now once we have registered a database in Database Sources panel, we can't change the Database Name because it is always grayed out but the server name, user name and password can be changed.
Actually I have mentioned this issue to our team before starting development and they proposed me the schema that I can use, but suddenly our client did not agree with it that we have been using, and then our client asked us to use another schema, FYI we are using Oracle Database as the data source.
Can you guys here share how to manage this situation.
Thanks,
Rudy
---------------
For Essbase Studio, the configuration metadata are saved as CP_tablenames, look for the CP tables, and make proper database change for the database name.
1. Make a Oracle backup for the CP tables before you change the metadata so that you can get back in case if error
2. Change the CP_CONNECTION TABLE, NAME column
3. Change the CP_SOURCE table, column DNAME, for example, it is called TBC.Sales, change to NewDB.Sales
I am not sure if there are other table also need to be updated, anyway, when you update the DBname in the metadata level, everything should be consistent in all of the related tables. Here, I assume the new db has the same table names as the old db, if the new db has very different table names, recreating everything may be easier and has less risk.
Bob Wang
Actually I have mentioned this issue to our team before starting development and they proposed me the schema that I can use, but suddenly our client did not agree with it that we have been using, and then our client asked us to use another schema, FYI we are using Oracle Database as the data source.
Can you guys here share how to manage this situation.
Thanks,
Rudy
---------------
For Essbase Studio, the configuration metadata are saved as CP_tablenames, look for the CP tables, and make proper database change for the database name.
1. Make a Oracle backup for the CP tables before you change the metadata so that you can get back in case if error
2. Change the CP_CONNECTION TABLE, NAME column
3. Change the CP_SOURCE table, column DNAME, for example, it is called TBC.Sales, change to NewDB.Sales
I am not sure if there are other table also need to be updated, anyway, when you update the DBname in the metadata level, everything should be consistent in all of the related tables. Here, I assume the new db has the same table names as the old db, if the new db has very different table names, recreating everything may be easier and has less risk.
Bob Wang
12/31/09
Hyperion Web Analysis

12/27/09
Java Tips
- Inheritance is the mechanism that a sub class inherit the behavior and attributes of a super class.
- An interface is a clollection of methods that indicate a class has some behavior in addition to what it inherits from its superclasses. The methods included in an interface do not define this behavior, that task is left for the classes that implement the inteface. To use an interface, include implements keyword as part of your class definition
public class AnimationSign extends javax.swing.JApplet
implements Runable {...} - Overriding: the method created in the sub class has the same nane as the super class, this is called overrriding.
- Package is a way of grouping related classes and interfaces. Such as: java.awt.*,java.lang.*.
- Literal: A literal is any number,text,or other information that directly represents a value. include: number literal(1,2,3), boolean literal(true,false),character literal(\n,\t),string literal("sss").
- A reference is an address that indicates where an object's variable and methods are stored.
- Casting between primitive types enables you to convert the value of one type to another primitive type. such as from int to float. Sample: (int)(x/y),(classname)object,(typename)value.
- To find out what an object's class is: String name = key.getClass().getName();
- instanceof operator return true or false: "Texta" instanceof String //true
- this keyword refer to the current object: t = this.x;
- Overloading: Methods with the same name but with different number of arguments or/and data type.
- Constructor mrthod is a method that is called on an object when it is created. The method has the same name as the class. this(arg1,arg2,arg3) can be used to call a constructor method. Constructor can be overloaded too.
- Use the super keyword to call the original method from inside a method definition:
void mymethod(String a, String b) {super.mymethod(a,b);} - finalizer method is called just before the object is collected for garbage and has its memory reclaimed.
protected void finalize() throws Throwable {super.finalize();} Finalizer method is used for optimizing the removal of an object. In most cases, you don't need to use finalize(0 at all - Applet runs on browser that support Java.
- Painting is how an applet displays something onscreen. repaint();
- Java archive is a collection of Java classes and other files packaged into a single file.
jar cf Animated.jar *.class *.gif - Swing is a part of the Java Foundation Classes library, provide a way to offer a graphical user interface. The swing is an extension of awt. javax.swing, javax.swing.JFrame,javax.swing.JWindow. Two other packages that are used with graphical user interface programming are java.awt and java.awt.event
- Threads are parts od program that are set up to run on their own while the rest of program does something else. This is called multitasking because the program can handle more than one tasks simultaneously.
- final class cannot be subclassed
- You can define a class inside a class, as if it were a method or a variable.These classes are called inner classes. Inner class are invisible to all other classes,no need to worry about the name conflicts between it and other classes.
public class Inner extends javax.swing.Applet {...} - Exception catch:
try{}
catch (IOExceptio e){}
catch (ClassNotFoundException e){}
catch (InterrptedException e){}
finally{
} - finnally statement is actually useful outside exceptions,you can aalso use it to execute cleanup code after s return,a break,or a continue inside loops.
- The throw clause: public boolean myMethod(int x,int y) throws AnException {}
- A digital signiture is an encriped file that accompany a program indicating exactly from whom the files come from. The document that represents this digital signiture is called a certificate.
- java.io: FileInputStream and FileOutputStream - Byte streams stored in files on disk,CD-ROM,or other storage devices
- java.io: DataInputStream and DataOutputStream - A filtered byte stream from which data such as integers and floating-point numbers can be read
- Java handles access to external data via the use of a class of objects called streams. A stream is an object that carries data from one place to another.
- Object serialization: the capability to reaad and write an object using steams.
- Objects can be serialized to disk on a single machine or can be serialized across a network.
- Persistence : the capability of an object to exist and function outside the program that created it. Serialization enables object persistence.
FileOutputStream disk = new FileOutputStream("SavedObject.dat")
ObjectOutputStream obj = new ObjectOutputStream(disk) - RMI(remote method invocation): creates Java application that can talk to other Java application over a network. RMI allows an application to call methods and access variables inside another application, which might be running in a different Java Envirnment or different OS altogether, and pass objects back and forth over a network connection.
java.rmi.server, java.rmi.registry, java.rmi.dgc - Before code with RMI, use rmic command-line program to generate the Stub and Skeleton layers so that RMI can actually work between the two sides of the process
- RPC(Remote Procedure calls): sends only procedure calls over the wire, while RMI actually pass the whole object.
- Socket: Java provides the Socket and ServerSocket classes as an abstraction of standard TCP socket program techniques. The Socket class provides s client side socket interface similar to standard UNIX socket.
Socket connection = new Socket(hostName, portNum);
connection.setSoTimeOut(50000);
BufferedInputStream bis = new BufferedInputStream(connection.getInputStream());
DataInputStream in = new DataInputStream(bis);
BufferedOutputStream bos = new BufferedOutputStream(connection.getOutputStream());
DataOutputStream out = new DataOutputStream(bos);
- Sever Side sockets work similar to client side sockets, with the exception of the accept() method. The accept() method accepts a connection from that client..
- JavaBeans is an architecture and platform independent set of classes for crreating and using Java software components. You can drop a JavaBean component directly into an application without writing any code.
- Java Database connectiion, 2 ways: JDBC-ODBC bridge, or JDBC drivers
JDBC-ODBC bridge allows JDBC drivers to be used as ODBC drivers by converting JDBC method calls into ODBC function calls. The next is a sample for JDBC-ODBC:
Connection payday = DriverManager.getConnection("jdbc.odbc:Payroll","Doc","Notnow"); - The next is a sample for JDBC:
Connection payday = DriverManager.getConnection("jdbc:JDataConnect://localhost:1150/Presidents","",""); - Java Data Structure
- BitSet class implements a group of bits or flags that can be set an cleared individually. class Somebits {
public static final int READABLE = 0;
public static final int WRITABLE = 1;
public static final int STREAMABLE = 2;
public static final int FLEXIBLE = 3;
}
- Vectr class implements an extendable array of objects
Vector v = new Vector();
v.add("Bob");
- Stacks are a classic data structure used, last in, first out
Stack s = new Stack();
s.push("One");
s.push("two");
String s1 = (String)s.pop();
- Map interface defines a framework for implementing a basic key-mapped data structure.
- Hashtable class is derived from dictionary, implements the Map interface, and provides a complete implementation of a key-mapped data structure.
12/26/09
Hyperion Report System Migration
Migration involves migrating information from the source system to Oracle's Hyperion® Shared Services and the Oracle's Hyperion Reporting and Analysis Repository.
Migration involves: users, groups, roles, and repository content. The source systems include:
. Brio Portal 7.0.5 or later
. BrioONE (Brio Portal 7.0.5 or later and OnDemand Server 6.6.4 or later)
. Brio Intelligence Server (OnDemand Server and Broadcast Server 6.6.4 or later)
. Hyperion Analyzer 6.5, 7.0.1, 7.2, or 7.2.1
. Hyperion Performance Suite 8.x
. Hyperion Reports 7.0.x or 7.2
-----------------------------------------------
Prerequisites for Using the Migration Utility:
. Administrator permission on both source and target system
. Disable the Harvester service.
. If your target system is Oracle, set the NLS_LENGTH_SEMANTICS parameter to char.
nls_length_semantics=char
. For systems using X-Windows on UNIX, start vncserver so that it uses (at a minimum) HiColor.
For example, vncserver -depth 15 or vncserver -depth 16.
. If the source is Brio Portal or Hyperion Performance Suite 8: turn off the services on the source and target systems
. If the source is Brio Intelligence: 1. Turn off the services on the source system. (The services on the target system should stay running.). 2. For UNIX systems, add the BQ_FONT_PATH to the services.sh file located in the/BrioPlatform/bin directory and restart the services. The BQ_FONT_PATH environment variable is needed by the Interactive Reporting Service on the target system to ensure that BQY jobs and documents are rendered properly in the new environment.
------------------------------------------------------------
Other Considerations:
. Special Symbols in Users and Groups
. Invalid Characters in Workspace
. SmartCuts - You need reconfigure the SmartCut in source so that the characters are valid in new Hyperion Workspace.
------------------------------------------------------------
Run Migration Wizard and follow the steps:
About Migrating from Brio Portal, steps:
● Defining the Location of the Portal Repository Database
● Identifying Portal Groups with Circular References
● Selecting the Objects to Migrate
● Defining Reporting and Analysis Repository Database Information
● Defining the Location of the Reporting and Analysis Repository Database
● Defining the Location of the Shared Services Server
● Defining User/Group Names, Descriptions and Passwords
● Reviewing User Names
● Reviewing Group Names
● Mapping Hosts
● Defining Additional Migration Options
● Running the Migration
-----------------------------------------------
Other options:
1. LDAP and Shared Service backup
2. Export the security file to external file and modification and load back
3. Source and target run in different computer servers.
4. The migration should not affect the original content in source server normally
5. Migration to a test server first before production migration
6. UNIT test include: 1). general functionality test, such as: can we see the report from workspace? 2). User security test 3). Repository object test, such as the report job, web folder 4).Report modification because of version difference.
Migration involves: users, groups, roles, and repository content. The source systems include:
. Brio Portal 7.0.5 or later
. BrioONE (Brio Portal 7.0.5 or later and OnDemand Server 6.6.4 or later)
. Brio Intelligence Server (OnDemand Server and Broadcast Server 6.6.4 or later)
. Hyperion Analyzer 6.5, 7.0.1, 7.2, or 7.2.1
. Hyperion Performance Suite 8.x
. Hyperion Reports 7.0.x or 7.2
-----------------------------------------------
Prerequisites for Using the Migration Utility:
. Administrator permission on both source and target system
. Disable the Harvester service.
. If your target system is Oracle, set the NLS_LENGTH_SEMANTICS parameter to char.
nls_length_semantics=char
. For systems using X-Windows on UNIX, start vncserver so that it uses (at a minimum) HiColor.
For example, vncserver -depth 15 or vncserver -depth 16.
. If the source is Brio Portal or Hyperion Performance Suite 8: turn off the services on the source and target systems
. If the source is Brio Intelligence: 1. Turn off the services on the source system. (The services on the target system should stay running.). 2. For UNIX systems, add the BQ_FONT_PATH to the services.sh file located in the
------------------------------------------------------------
Other Considerations:
. Special Symbols in Users and Groups
. Invalid Characters in Workspace
. SmartCuts - You need reconfigure the SmartCut in source so that the characters are valid in new Hyperion Workspace.
------------------------------------------------------------
Run Migration Wizard and follow the steps:
About Migrating from Brio Portal, steps:
● Defining the Location of the Portal Repository Database
● Identifying Portal Groups with Circular References
● Selecting the Objects to Migrate
● Defining Reporting and Analysis Repository Database Information
● Defining the Location of the Reporting and Analysis Repository Database
● Defining the Location of the Shared Services Server
● Defining User/Group Names, Descriptions and Passwords
● Reviewing User Names
● Reviewing Group Names
● Mapping Hosts
● Defining Additional Migration Options
● Running the Migration
-----------------------------------------------
Other options:
1. LDAP and Shared Service backup
2. Export the security file to external file and modification and load back
3. Source and target run in different computer servers.
4. The migration should not affect the original content in source server normally
5. Migration to a test server first before production migration
6. UNIT test include: 1). general functionality test, such as: can we see the report from workspace? 2). User security test 3). Repository object test, such as the report job, web folder 4).Report modification because of version difference.
Essbase Migration
EAM provides a Wizard for migrating Essbase applications, databases, and user/group security from one server to another. For example, you might migrate an application from a development to test server or from a production to a test server to try out a new release of Essbase software. With Migration Wizard, you can migrate application and database objects and security without leaving the Administration Services console.
The following points apply to applications migrated using Migration Wizard:
1. Only application and database objects and user/group security are migrated. No data is transferred.
2. Objects and security on the source server are unchanged. Migration Wizard makes copies on the target server.
3. Source and target servers may be on different operating systems. For example, you can migrate an application from a Windows to a Unix server.
The data can be loded to the target after the running of Migration Wizard.
Prerequisites:
Before starting this tutorial, you should:
1. Have both an Essbase Release 7.1.0 server and an Essbase Release 9.3.1 server installed and running.
2. Utilize Essbase native security on both servers.
3. Have an Essbase application on the Release 7.1.0 server available for migrating. This tutorial migrates an application called Mexcorp.
The following points apply to applications migrated using Migration Wizard:
1. Only application and database objects and user/group security are migrated. No data is transferred.
2. Objects and security on the source server are unchanged. Migration Wizard makes copies on the target server.
3. Source and target servers may be on different operating systems. For example, you can migrate an application from a Windows to a Unix server.
The data can be loded to the target after the running of Migration Wizard.
Prerequisites:
Before starting this tutorial, you should:
1. Have both an Essbase Release 7.1.0 server and an Essbase Release 9.3.1 server installed and running.
2. Utilize Essbase native security on both servers.
3. Have an Essbase application on the Release 7.1.0 server available for migrating. This tutorial migrates an application called Mexcorp.
12/25/09
Embedded Java API - Hyperion Application Builder
The next picture is a sample that is developed by Hyperion Application Builder:

The Embedded Java Application Programming Interface (JAPI) feature is a simple deployment of the JAPI solution. Enabling this feature will provide the Application Builder for .NET applications to establish connection with the Essbase servers even when Provider Services is not installed, see Figure. The connection protocol between the Application Builder for .NET
applications and the Essbase servers is TCP/IP or HTTPS.
The embedded JAPI deployment for Application Builder for .NET includes .jar files and property files. When you enable the embedded JAPI feature, the Application Programming Interface (API) client will include these .jar files and property files in the Application Builder for .NET application.
Prerequisites
Some of the current Java API customers may require only Java API functionality, and will not require a full installation of the Provider Services product with the extended functionality such as Clustering, High Availability, Connection Pooling, and XMLA provider.
Complete these prerequisites to enable this feature:
● %APS_HOME% should contain both \bin and \data folders
● %APS_HOME%\bin should contain essbase.properties file
● Update the Habnet.properties file.
In \HABNET_HOME\products\Essbase\habnet\Server\lib\, In Habnet.properties file include value EDSUrl=Embedded.
● From Essbase server installation location: HABNET_HOME\products\Essbase\habnet\server\lib copy the Essbase.properties file to %APS_HOME%\bin. Enabling Embedded JAPI
The embedded JAPI feature is available when you install this release of Application Builder for .NET. However, to enable this feature, you must do some updates to the Habnet.properties file. With this feature update to the Application Builder for .NET release, to establish connection between Application Builder for .NET applications and Essbase has a option of using either Provider Services or embedded JAPI depending on the requirement.
This utility is run based on the following assumptions:
● The password information of the Essbase servers are read without any encryption.
● The user ID and password information is used for authentication and this utility will update only the server name information in the domain.db file.
● The utility will read the environment variables APS_HOME and ABNET_HOME to get the location information of the files domain.db and essbase_servers.xml.
➤ To enable the embedded JAPI utility:
1 In the Habnet.properties file, for EDSUrl provide the value Embedded.
2 Save and close the Habnet.properties file.
➤ To revert to Provider Services:
1 In the Habnet.properties file, for EDSUrl provide the value EDSUrl = http://
name>:/aps/JAPI.
2 Save and close the Habnet.properties file.
Managing the Embedded JAPI Feature
This feature offers a utility that gathers the Essbase server information (server name, user ID,and password) from the XML template file essbase_servers.xml and updates the domain.db file. The user has a privilege to add the server information in essbase_servers.xml to "add","delete" and "None" actions to update the domain.db file.
The essbase_servers.xml file must include these server information:
"password">
"password">
In essbase_servers.xml file the action attribute can have one of the following values:
Add, Delete and None. Add value adds the specified server information to domain.db file.
Delete value deletes the specified server information from the domain.db file. None value means no action performed on the domain.db file. The Application Builder for .NET applications will use this information that is present in the domain.db file to communicate with the Essbase servers. The domain.db file is present in the folder APS_HOME\data.
Running the Embedded JAPI Utility
As prerequisite, the essbase_servers.xml file must be present in the location \HABNET_HOME\products\Essbase\habnet\Server\lib. Once this utility is run, the domain.db file is created in the location APS_HOME\data.
You can run the embedded JAPI utility from the Application Builder for .NET installation directories. The embedded JAPI utilty will update the server information in the domain.db file.
➤ To run the embedded JAPI utility and update the XML template file:
1 For Windows: from %HABNET_HOME%\products\Essbase\habnet\Server\bin\, run command
ESSJapiUtil.bat.
2 For Unix: from $HABNET_HOME/products/Essbase/habnet/Server/bin/, run command
ESSJapiUtil.sh.
You can register or deregister the Essbase servers with or without resetting the password or exporting the Essbase server information.
➤ To register the Essbase servers and reset the Essbase server passwords:
1 For Windows: from %HABNET_HOME%\products\Essbase\habnet\Server\bin\, run command
ESSJapiUtil.bat register.
2 For Unix: from $HABNET_HOME/products/Essbase/habnet/Server/bin/, run command
ESSJapiUtil.sh register.
➤ To export the Essbase server information (This command will not record the password information):
1 In \HABNET_HOME\products\Essbase\habnet\Server\lib create the
essbase_servers_export.xml file.
2 For Windows: from %HABNET_HOME%\products\Essbase\habnet\Server\bin\, run command
ESSJapiUtil.bat export.
3 For Unix: from $HABNET_HOME/products/Essbase/habnet/Server/bin/, run command
ESSJapiUtil.sh export.
➤ To register Essbase servers without passwords reset:
1 For Windows: from %HABNET_HOME%\products\Essbase\habnet\Server\bin\, run command
ESSJapiUtil.bat registernoreset.
2 For Unix: from $HABNET_HOME/products/Essbase/habnet/Server/bin/, run command
ESSJapiUtil.sh registernoreset.

applications and the Essbase servers is TCP/IP or HTTPS.
The embedded JAPI deployment for Application Builder for .NET includes .jar files and property files. When you enable the embedded JAPI feature, the Application Programming Interface (API) client will include these .jar files and property files in the Application Builder for .NET application.
Prerequisites
Some of the current Java API customers may require only Java API functionality, and will not require a full installation of the Provider Services product with the extended functionality such as Clustering, High Availability, Connection Pooling, and XMLA provider.
Complete these prerequisites to enable this feature:
● %APS_HOME% should contain both \bin and \data folders
● %APS_HOME%\bin should contain essbase.properties file
● Update the Habnet.properties file.
In \HABNET_HOME\products\Essbase\habnet\Server\lib\, In Habnet.properties file include value EDSUrl=Embedded.
● From Essbase server installation location: HABNET_HOME\products\Essbase\habnet\server\lib copy the Essbase.properties file to %APS_HOME%\bin. Enabling Embedded JAPI
The embedded JAPI feature is available when you install this release of Application Builder for .NET. However, to enable this feature, you must do some updates to the Habnet.properties file. With this feature update to the Application Builder for .NET release, to establish connection between Application Builder for .NET applications and Essbase has a option of using either Provider Services or embedded JAPI depending on the requirement.
This utility is run based on the following assumptions:
● The password information of the Essbase servers are read without any encryption.
● The user ID and password information is used for authentication and this utility will update only the server name information in the domain.db file.
● The utility will read the environment variables APS_HOME and ABNET_HOME to get the location information of the files domain.db and essbase_servers.xml.
➤ To enable the embedded JAPI utility:
1 In the Habnet.properties file, for EDSUrl provide the value Embedded.
2 Save and close the Habnet.properties file.
➤ To revert to Provider Services:
1 In the Habnet.properties file, for EDSUrl provide the value EDSUrl = http://
name>:
2 Save and close the Habnet.properties file.
Managing the Embedded JAPI Feature
This feature offers a utility that gathers the Essbase server information (server name, user ID,and password) from the XML template file essbase_servers.xml and updates the domain.db file. The user has a privilege to add the server information in essbase_servers.xml to "add","delete" and "None" actions to update the domain.db file.
The essbase_servers.xml file must include these server information:
"password">
"password">
In essbase_servers.xml file the action attribute can have one of the following values:
Add, Delete and None. Add value adds the specified server information to domain.db file.
Delete value deletes the specified server information from the domain.db file. None value means no action performed on the domain.db file. The Application Builder for .NET applications will use this information that is present in the domain.db file to communicate with the Essbase servers. The domain.db file is present in the folder APS_HOME\data.
Running the Embedded JAPI Utility
As prerequisite, the essbase_servers.xml file must be present in the location \HABNET_HOME\products\Essbase\habnet\Server\lib. Once this utility is run, the domain.db file is created in the location APS_HOME\data.
You can run the embedded JAPI utility from the Application Builder for .NET installation directories. The embedded JAPI utilty will update the server information in the domain.db file.
➤ To run the embedded JAPI utility and update the XML template file:
1 For Windows: from %HABNET_HOME%\products\Essbase\habnet\Server\bin\, run command
ESSJapiUtil.bat.
2 For Unix: from $HABNET_HOME/products/Essbase/habnet/Server/bin/, run command
ESSJapiUtil.sh.
You can register or deregister the Essbase servers with or without resetting the password or exporting the Essbase server information.
➤ To register the Essbase servers and reset the Essbase server passwords:
1 For Windows: from %HABNET_HOME%\products\Essbase\habnet\Server\bin\, run command
ESSJapiUtil.bat register.
2 For Unix: from $HABNET_HOME/products/Essbase/habnet/Server/bin/, run command
ESSJapiUtil.sh register.
➤ To export the Essbase server information (This command will not record the password information):
1 In \HABNET_HOME\products\Essbase\habnet\Server\lib create the
essbase_servers_export.xml file.
2 For Windows: from %HABNET_HOME%\products\Essbase\habnet\Server\bin\, run command
ESSJapiUtil.bat export.
3 For Unix: from $HABNET_HOME/products/Essbase/habnet/Server/bin/, run command
ESSJapiUtil.sh export.
➤ To register Essbase servers without passwords reset:
1 For Windows: from %HABNET_HOME%\products\Essbase\habnet\Server\bin\, run command
ESSJapiUtil.bat registernoreset.
2 For Unix: from $HABNET_HOME/products/Essbase/habnet/Server/bin/, run command
ESSJapiUtil.sh registernoreset.
Application Builder for .NET
Application Builder for .NET provides a comprehensive set of OLAP-aware classes for data navigation, selection, reporting, and visualization to assist you in building custom analytical applications. These controls provide you with the tools to quickly create and deploy applications in stand-alone, client-server, Web, or distributed processing environments. Application Builder for .NET is a component of the Oracle Enterprise Performance Management system that provides an application development workbench for companies wanting to use the Microsoft .NET Framework to create tailored business performance management solutions. Application Builder for .NET includes the following key features:
● Drag and Drop components for creating OLAP aware applications for Web and Windows using MS Visual Studio.Net
● .NET Framework compatibility
● Web Service -based architecture (SOAP)
Application Builder for .NET provides the following functionality:
● Base classes. These classes contain basic OLAP functionality and encapsulate functionality necessary to connect to and perform operations on Essbase applications and databases.
● Dialog components. These classes encapsulate the functionality of Essbase dialog boxes, including the sign-on and member selection dialog boxes.
To develop Application Builder for .NET applications within Visual Studio for .NET, perform the following steps:
● Install and configure Microsoft Visual Studio for .NET.
● Install Application Builder for .NET and note which directory contains theApplication Builder for .NET assemblies.
● If you are developing an ASP .NET (Active Server Pages) application, install or ensure access to an instance of Microsoft Internet Information Server (IIS).
● If you are developing applications using Microsoft Office Web Components (OWC11), you may need to add Microsoft Office Primary Interop Assemblies and install additional assemblies available from http://www.microsoft.com/.
● Install or ensure access to an Essbase server and application.
This guide assumes that you will be using the Sample application and Basic database installed with Essbase.
● Ensure that the Application Builder for .NET .WAR file has been applied to your Web application server.
● Ensure that Oracle Hyperion Provider Services™ is running, and that your application server can access it.
● Drag and Drop components for creating OLAP aware applications for Web and Windows using MS Visual Studio.Net
● .NET Framework compatibility
● Web Service -based architecture (SOAP)
Application Builder for .NET provides the following functionality:
● Base classes. These classes contain basic OLAP functionality and encapsulate functionality necessary to connect to and perform operations on Essbase applications and databases.
● Dialog components. These classes encapsulate the functionality of Essbase dialog boxes, including the sign-on and member selection dialog boxes.
To develop Application Builder for .NET applications within Visual Studio for .NET, perform the following steps:
● Install and configure Microsoft Visual Studio for .NET.
● Install Application Builder for .NET and note which directory contains theApplication Builder for .NET assemblies.
● If you are developing an ASP .NET (Active Server Pages) application, install or ensure access to an instance of Microsoft Internet Information Server (IIS).
● If you are developing applications using Microsoft Office Web Components (OWC11), you may need to add Microsoft Office Primary Interop Assemblies and install additional assemblies available from http://www.microsoft.com/.
● Install or ensure access to an Essbase server and application.
This guide assumes that you will be using the Sample application and Basic database installed with Essbase.
● Ensure that the Application Builder for .NET .WAR file has been applied to your Web application server.
● Ensure that Oracle Hyperion Provider Services™ is running, and that your application server can access it.
Essbase Studio
Essbase Studio only exists in version 11, it is derived from earlier Essbase Integration Service, but it is more powerful than EIS. It is used to design the Essbase outline from RLDB data source and flat file.
Also, it has a functonality that can migrate EIS catalog to Essbase Studio Catalog. Same as EIS, a common metadata repository, or catalog, captures all metadata related to all Essbase applications built in the enterprise and allows the reuse of metadata at the lowest level of granularity. The catalog gives Essbase Studio knowledge of the common metadata that is shared across the various applications enterprise-wide.The metadata catalog is still saved in RLDB, it describes the metadata repository.
The Source Navigator, displayed by default in the right pane of the Essbase Studio Console, has two tabs, the Data Sources tab and the Minischemas tab.
. Data Sources tab—Lists the physical data sources to which you have created connections. You can also launch the Connection Wizard from this tab, where you create data source connections.
. Minischemas tab—Lists the graphical representations of the tables you select from one or more data sources connections. You can create minischemas when creating data source connections, or you can create them later.
Also, it has a functonality that can migrate EIS catalog to Essbase Studio Catalog. Same as EIS, a common metadata repository, or catalog, captures all metadata related to all Essbase applications built in the enterprise and allows the reuse of metadata at the lowest level of granularity. The catalog gives Essbase Studio knowledge of the common metadata that is shared across the various applications enterprise-wide.The metadata catalog is still saved in RLDB, it describes the metadata repository.
The Source Navigator, displayed by default in the right pane of the Essbase Studio Console, has two tabs, the Data Sources tab and the Minischemas tab.
. Data Sources tab—Lists the physical data sources to which you have created connections. You can also launch the Connection Wizard from this tab, where you create data source connections.
. Minischemas tab—Lists the graphical representations of the tables you select from one or more data sources connections. You can create minischemas when creating data source connections, or you can create them later.
12/20/09
Informatica PowerCenter ETL steps
Informatica PowerCenter is included inside Hyperion Integration Management now. It has another name called DIM as a Hyperion component. The basics steps:
1. Create the 1st repository using Workflow Manager
2. Set up the Source connection and Target connection using Workflow Manager
3. Create the target tables using Designer->Tools->Warehouse Designer, select create table and drop table, don't need to add primary key
4. Use Designer->Tools->Transformation Developer to set up the transformation rules, such as : Max(), Min(), and some more complicated functions
4. Using Mapping Designer to set the mapping between the source tables and the target tables, and drag in the transformation objects. Save the repository
5. Use Workflow manager->Session->Task, to create a session that include the previous mapping
6. Create the work flow that include the session task
7. Everytime if you change the mapping and the transformation,you need to refresh the session and workflow, there is no refresh button, but you need to edit the connections and save the repository and validate. This is important even if you make a slightly change in the mapping.
8. Run the workflow and see it in the workflow onitor.
1. Create the 1st repository using Workflow Manager
2. Set up the Source connection and Target connection using Workflow Manager
3. Create the target tables using Designer->Tools->Warehouse Designer, select create table and drop table, don't need to add primary key
4. Use Designer->Tools->Transformation Developer to set up the transformation rules, such as : Max(), Min(), and some more complicated functions
4. Using Mapping Designer to set the mapping between the source tables and the target tables, and drag in the transformation objects. Save the repository
5. Use Workflow manager->Session->Task, to create a session that include the previous mapping
6. Create the work flow that include the session task
7. Everytime if you change the mapping and the transformation,you need to refresh the session and workflow, there is no refresh button, but you need to edit the connections and save the repository and validate. This is important even if you make a slightly change in the mapping.
8. Run the workflow and see it in the workflow onitor.
12/15/09
Java - the package list
com.sqribe.rm.*
- Hyperion Performance Suite classes
com.essbase.api.*
- Hyperion Essbase API classes
java.io.*
- input, output
java.io.File
- It is the central class in working with files and directories
java.swing.*
- an API for providing a graphical user interface (GUI) for Java programs.
java.awt.*
- Contains all of the classes for creating user interfaces and for painting graphics and images.
java.awt.event.*
- Provides interfaces and classes for dealing with different types of events fired by AWT components.
java.util.*
- The package java.util contains a variety of utility classes including the collections framework,
internationalization, String utilities, etc
java.lang
- Provides classes that are fundamental to the design of the Java programming language.
- Hyperion Performance Suite classes
com.essbase.api.*
- Hyperion Essbase API classes
java.io.*
- input, output
java.io.File
- It is the central class in working with files and directories
java.swing.*
- an API for providing a graphical user interface (GUI) for Java programs.
java.awt.*
- Contains all of the classes for creating user interfaces and for painting graphics and images.
java.awt.event.*
- Provides interfaces and classes for dealing with different types of events fired by AWT components.
java.util.*
- The package java.util contains a variety of utility classes including the collections framework,
internationalization, String utilities, etc
java.lang
- Provides classes that are fundamental to the design of the Java programming language.
12/14/09
Java-Object Serialization
.Object serialization: the capability to read and write an object using stream.
.Reflection:the capability of one object to learn details about another object
.Remote method invocation: the capability to query another object to investigate its features and call its methods.
A programming concept involved in object serialization is persistence - the capability of an object to exist and function outside the pragram that create it.
An object indicates that it can be used with streams by implementing the Serializable interface. This interface, which is part of the java.io package, differs from other interfaces you have worked withit does not contain any methods that must be included in the classes that implement it. The sole purpose of Serializable is to indicate that objects of that class can be stored an retrieved in serial form.
The following code creates an output stream and an associated object output stream:
FileOutputStream disk = new FileOutputStream("SavedObject.dat");
ObjectOutputStream obj = new ObjectOutputStream(disk);
The object to Disk program:
----------
import java.io.*;
import java.util.*;
public class ObjectToDisk {
public static void main(String[] arguments) {
Message mess = new Message();
String author = "Sam Wainwright, London";
String recipient = "George Bailey, Bedford Falls";
String[] letter = { "Mr. Gower cabled you need cash. Stop.",
"My office instructed to advance you up to twenty-five",
"thousand dollars. Stop. Hee-haw and Merry Christmas." };
Date now = new Date();
mess.writeMessage(author, recipient, now, letter);
try {
FileOutputStream fo = new FileOutputStream("Message.obj");
ObjectOutputStream oo = new ObjectOutputStream(fo);
oo.writeObject(mess);
oo.close();
System.out.println("Object created successfully.");
} catch (IOException e) {
System.out.println("Error -- " + e.toString());
}
}
}
class Message implements Serializable {
int lineCount;
String from, to;
Date when;
String[] text;
void writeMessage(String inFrom,
String inTo,
Date inWhen,
String[] inText) {
text = new String[inText.length];
for (int i = 0; i < inText.length; i++)
text[i] = inText[i];
lineCount = inText.length;
to = inTo;
from = inFrom;
when = inWhen;
}
}
--------------
The object from disk program:
import java.io.*;
import java.util.*;
public class ObjectFromDisk {
public static void main(String[] arguments) {
try {
FileInputStream fi = new FileInputStream("message.obj");
ObjectInputStream oi = new ObjectInputStream(fi);
Message mess = (Message) oi.readObject();
System.out.println("Message:\n");
System.out.println("From: " + mess.from);
System.out.println("To: " + mess.to);
System.out.println("Date: " + mess.when + "\n");
for (int i = 0; i < mess.lineCount; i++)
System.out.println(mess.text[i]);
oi.close();
} catch (Exception e) {
System.out.println("Error -- " + e.toString());
}
}
}
.Reflection:the capability of one object to learn details about another object
.Remote method invocation: the capability to query another object to investigate its features and call its methods.
A programming concept involved in object serialization is persistence - the capability of an object to exist and function outside the pragram that create it.
An object indicates that it can be used with streams by implementing the Serializable interface. This interface, which is part of the java.io package, differs from other interfaces you have worked withit does not contain any methods that must be included in the classes that implement it. The sole purpose of Serializable is to indicate that objects of that class can be stored an retrieved in serial form.
The following code creates an output stream and an associated object output stream:
FileOutputStream disk = new FileOutputStream("SavedObject.dat");
ObjectOutputStream obj = new ObjectOutputStream(disk);
The object to Disk program:
----------
import java.io.*;
import java.util.*;
public class ObjectToDisk {
public static void main(String[] arguments) {
Message mess = new Message();
String author = "Sam Wainwright, London";
String recipient = "George Bailey, Bedford Falls";
String[] letter = { "Mr. Gower cabled you need cash. Stop.",
"My office instructed to advance you up to twenty-five",
"thousand dollars. Stop. Hee-haw and Merry Christmas." };
Date now = new Date();
mess.writeMessage(author, recipient, now, letter);
try {
FileOutputStream fo = new FileOutputStream("Message.obj");
ObjectOutputStream oo = new ObjectOutputStream(fo);
oo.writeObject(mess);
oo.close();
System.out.println("Object created successfully.");
} catch (IOException e) {
System.out.println("Error -- " + e.toString());
}
}
}
class Message implements Serializable {
int lineCount;
String from, to;
Date when;
String[] text;
void writeMessage(String inFrom,
String inTo,
Date inWhen,
String[] inText) {
text = new String[inText.length];
for (int i = 0; i < inText.length; i++)
text[i] = inText[i];
lineCount = inText.length;
to = inTo;
from = inFrom;
when = inWhen;
}
}
--------------
The object from disk program:
import java.io.*;
import java.util.*;
public class ObjectFromDisk {
public static void main(String[] arguments) {
try {
FileInputStream fi = new FileInputStream("message.obj");
ObjectInputStream oi = new ObjectInputStream(fi);
Message mess = (Message) oi.readObject();
System.out.println("Message:\n");
System.out.println("From: " + mess.from);
System.out.println("To: " + mess.to);
System.out.println("Date: " + mess.when + "\n");
for (int i = 0; i < mess.lineCount; i++)
System.out.println(mess.text[i]);
oi.close();
} catch (Exception e) {
System.out.println("Error -- " + e.toString());
}
}
}
Java - display all methods in a class
This method can display all metjods inside a class. This will use the Class class, which is part of java.lang package, is used to learn about and create classes,interfaces,and primitive types. To try the below program, enter:
java SeeMethods java.util.Random, and you will get
Method: next()
Modifiers: protected synchronized
Return type: int
Parameters: int
Method: nextDouble()
Modifiers: public
Return type: double
Parameters:
......
--------------------------------
import java.lang.reflect.*;
public class SeeMethods {
public static void main(String[] arguments) {
Class inspect;
try {
if (arguments.length > 0)
inspect = Class.forName(arguments[0]);
else
inspect = Class.forName("SeeMethods");
Method[] methods = inspect.getDeclaredMethods();
for (int i = 0; i < methods.length; i++) {
Method methVal = methods[i];
Class returnVal = methVal.getReturnType();
int mods = methVal.getModifiers();
String modVal = Modifier.toString(mods);
Class[] paramVal = methVal.getParameterTypes();
StringBuffer params = new StringBuffer();
for (int j = 0; j < paramVal.length; j++) {
if (j > 0)
params.append(", ");
params.append(paramVal[j].getName());
}
System.out.println("Method: " + methVal.getName() + "()");
System.out.println("Modifiers: " + modVal);
System.out.println("Return Type: " + returnVal.getName());
System.out.println("Parameters: " + params + "\n");
}
} catch (ClassNotFoundException c) {
System.out.println(c.toString());
}
}
}
java SeeMethods java.util.Random, and you will get
Method: next()
Modifiers: protected synchronized
Return type: int
Parameters: int
Method: nextDouble()
Modifiers: public
Return type: double
Parameters:
......
--------------------------------
import java.lang.reflect.*;
public class SeeMethods {
public static void main(String[] arguments) {
Class inspect;
try {
if (arguments.length > 0)
inspect = Class.forName(arguments[0]);
else
inspect = Class.forName("SeeMethods");
Method[] methods = inspect.getDeclaredMethods();
for (int i = 0; i < methods.length; i++) {
Method methVal = methods[i];
Class returnVal = methVal.getReturnType();
int mods = methVal.getModifiers();
String modVal = Modifier.toString(mods);
Class[] paramVal = methVal.getParameterTypes();
StringBuffer params = new StringBuffer();
for (int j = 0; j < paramVal.length; j++) {
if (j > 0)
params.append(", ");
params.append(paramVal[j].getName());
}
System.out.println("Method: " + methVal.getName() + "()");
System.out.println("Modifiers: " + modVal);
System.out.println("Return Type: " + returnVal.getName());
System.out.println("Parameters: " + params + "\n");
}
} catch (ClassNotFoundException c) {
System.out.println(c.toString());
}
}
}
JavaBeans
JavaBean is a software object that interacts with other objects according to a strict set of guidelines - the JavaBean Specification. By following these guidlines, the bean can most easily be used with other objects. JavaBean is an architecture - and platform-independent set of classes for creating and using Java software components. JavaBean inherit "persistence".Persistence is handled automatically in JavaBean by using serialization mechanism. Serialization is the process of storing or retrieving information through a standard protocol. JavaBean specifies a rich of mechanisms for interaction between objects,along with common actions that most objectd will need to support,such as persistence and event handling.
With visual tools,you can use a variety of JavaBean components together without necessarily writing any code.JavaBeans components expose their own interfaces visually,providing a means to edit their properties without programming.Furthermore,by using a visual editor,you can drop a JavaBeans component directly into an application without writing any code.This is entirely new level of flexibility and reusability that was impossible in Java alone.
With visual tools,you can use a variety of JavaBean components together without necessarily writing any code.JavaBeans components expose their own interfaces visually,providing a means to edit their properties without programming.Furthermore,by using a visual editor,you can drop a JavaBeans component directly into an application without writing any code.This is entirely new level of flexibility and reusability that was impossible in Java alone.
Java - JDBC connect DB
Use JDBC driver to access DB.
import java.sql.*;
public class Presidents {
public static void main(String[] arguments) {
String data =
try {
Class.forName("JData2_0.sql.$Driver");
Connection conn = DriverManager.getConnection("jdbc:JDataConnect://localhost:1150/Presidents","username","password");
Statement st = conn.createStatement();
ResultSet rec = st.executeQuery(
"SELECT * FROM Contacts ORDER BY NAME");
while(rec.next()) {
System.out.println(rec.getString("NAME") + "\n"
+ rec.getString("ADDRESS1") + "\n"
+ rec.getString("ADDRESS2") + "\n"
+ rec.getString("PHONE") + "\n"
+ rec.getString("E-MAIL") + "\n");
}
st.close();
} catch (Exception e) {
System.out.println("Error -- " + e.toString());
}
}
}
import java.sql.*;
public class Presidents {
public static void main(String[] arguments) {
String data =
try {
Class.forName("JData2_0.sql.$Driver");
Connection conn = DriverManager.getConnection("jdbc:JDataConnect://localhost:1150/Presidents","username","password");
Statement st = conn.createStatement();
ResultSet rec = st.executeQuery(
"SELECT * FROM Contacts ORDER BY NAME");
while(rec.next()) {
System.out.println(rec.getString("NAME") + "\n"
+ rec.getString("ADDRESS1") + "\n"
+ rec.getString("ADDRESS2") + "\n"
+ rec.getString("PHONE") + "\n"
+ rec.getString("E-MAIL") + "\n");
}
st.close();
} catch (Exception e) {
System.out.println("Error -- " + e.toString());
}
}
}
Java - JDBC-ODBC bridge
JDBC is a set of classes that can be used to develop client/server database applications using Java. JDBC-ODBC bridge allows JDBC drivers to be used as ODBC drivers by coverting JDBC method into ODBC function calls. sun.jdbc.odbc.JdbcOdbcDriver is required.
import java.sql.*;
public class CoalTotals {
public static void main(String[] arguments) {
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
Connection conn = DriverManager.getConnection("jdbc:odbc:SampleDataSource", "username", "password");
Statement st = conn.createStatement();
ResultSet rec = st.executeQuery(
"SELECT * " +
"FROM Coal " +
"WHERE " +
"(Country='" + arguments[0] + "') " +
"ORDER BY Year");
System.out.println("FIPS\tCOUNTRY\t\tYEAR\t" +
"ANTHRACITE PRODUCTION");
while(rec.next()) {
System.out.println(rec.getString(1) + "\t"
+ rec.getString(2) + "\t\t"
+ rec.getString(3) + "\t"
+ rec.getString(4));
}
st.close();
} catch (SQLException s) {
System.out.println("SQL Error: " + s.toString() + " "+ s.getErrorCode() + " " + s.getSQLState());
} catch (Exception e) {
System.out.println("Error: " + e.toString()+ e.getMessage());
}
}
}
import java.sql.*;
public class CoalTotals {
public static void main(String[] arguments) {
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver");
Connection conn = DriverManager.getConnection("jdbc:odbc:SampleDataSource", "username", "password");
Statement st = conn.createStatement();
ResultSet rec = st.executeQuery(
"SELECT * " +
"FROM Coal " +
"WHERE " +
"(Country='" + arguments[0] + "') " +
"ORDER BY Year");
System.out.println("FIPS\tCOUNTRY\t\tYEAR\t" +
"ANTHRACITE PRODUCTION");
while(rec.next()) {
System.out.println(rec.getString(1) + "\t"
+ rec.getString(2) + "\t\t"
+ rec.getString(3) + "\t"
+ rec.getString(4));
}
st.close();
} catch (SQLException s) {
System.out.println("SQL Error: " + s.toString() + " "+ s.getErrorCode() + " " + s.getSQLState());
} catch (Exception e) {
System.out.println("Error: " + e.toString()+ e.getMessage());
}
}
}
12/10/09
Hyperion Planning Dimension Sequence
The order of dimensions is critical for the structure and performance of Essbase databases. Optimize performance by ordering dimensions according to these guidelines:
. Make Period and Account dense, and order dense dimensions from most to least dense. The most dense is usually Period, followed by Account. Dense dimensions calculate faster than sparse dimensions.
. Separate sparse dimensions into aggregating and non-aggregating dimensions. Place aggregating dimensions before non-aggregating dimensions. Order sparse dimensions from most to least dense. Aggregating dimensions, such as Account, aggregate, or consolidate,children into the parent to create new data. Non-aggregating dimensions, such as Scenario,
do not consolidate children to create data.
. Make Period and Account dense, and order dense dimensions from most to least dense. The most dense is usually Period, followed by Account. Dense dimensions calculate faster than sparse dimensions.
. Separate sparse dimensions into aggregating and non-aggregating dimensions. Place aggregating dimensions before non-aggregating dimensions. Order sparse dimensions from most to least dense. Aggregating dimensions, such as Account, aggregate, or consolidate,children into the parent to create new data. Non-aggregating dimensions, such as Scenario,
do not consolidate children to create data.
12/9/09
Essbase Migration Keys
1. Make hardware and the version upgrade.
2. Install the application on the new server.
3. Use the migration wizard, this would migrate all the objects, but not the data.
4. Import and export is the way to get the data after migration.
5. Open ports on the servers, make sure no port conflict.
6. Make sure the same language is selected
7. Create the ODBC drivers if SQL interface is used.
8. Put the customized Java functions in the UDF folder
9. Copy Substitution variables to the new server
10. Verify security on the new server, sometimes the migration wizard doe not do it properly
11. Check Essbase config file and copy over needed parameters
12. Do lots of testing of calc scripts, report scripts, and MDX scripts
2. Install the application on the new server.
3. Use the migration wizard, this would migrate all the objects, but not the data.
4. Import and export is the way to get the data after migration.
5. Open ports on the servers, make sure no port conflict.
6. Make sure the same language is selected
7. Create the ODBC drivers if SQL interface is used.
8. Put the customized Java functions in the UDF folder
9. Copy Substitution variables to the new server
10. Verify security on the new server, sometimes the migration wizard doe not do it properly
11. Check Essbase config file and copy over needed parameters
12. Do lots of testing of calc scripts, report scripts, and MDX scripts
12/7/09
Hyperion SQR Performance Tuning
SQR Performance and SQL Statements
Whenever a program contains a BEGIN-SELECT, BEGIN-SQL, or EXECUTE command, it performs a SQL statement. Processing SQL statements typically consumes significant computing resources. Tuning
SQL statements typically yields higher performance gains than tuning any other part of your program.
This paper focuses on SQR tools for simplifying SQL statements and reducing the number of SQL executions. There are several techniques, including:
• Simplify a complex select paragraph.
• Use LOAD-LOOKUP to simplify joins.
• Improve SQL performance with dynamic SQL.
• Examine SQL cursor status.
• Avoid temporary database tables.
• Create multiple reports in one pass.
• Tune SQR numerics.
• Compile SQR programs and use SQR Execute.
• Set processing limits.
• Buffer fetched rows.
• Run programs on the database server.
Simplifying a Complex Select Paragraph
With relational database design, information is often normalized by storing data entities in separate tables. To display the normalized information, we must write a select paragraph that joins these tables together. With many database systems, performance suffers when you join more than three or four tables in one select paragraph.
With SQR, we can perform multiple select paragraphs and nest them. In this way, we can break a large join into several simpler selects. For example, we can break a select paragraph that joins the orders and the products tables into two selects. The first select retrieves the orders in which we are interested. For each order that is retrieved, a second select retrieves the products that were ordered. The second select is correlated to the first select by having a condition such as:
where order_num = &order_num
This condition specifies that the second select retrieves only products for the current order.
Similarly, if the report is based on products that were ordered, you can make the first select retrieve the products and make the second select retrieve the orders for each product.
This method improves performance in many cases, but not all. To achieve the best performance, we need to experiment with the different alternatives.
Using LOAD-LOOKUP to Simplify Joins
Database tables often contain key columns, such as a employee id or customer number. To retrieve a certain piece of information, we join two or more tables that contain the same column. For example, to obtain a product description, we can join the orders table with the products table by using the product_code column as the key.
With LOAD-LOOKUP, you can reduce the number of tables that are joined in one select. Use this command with LOOKUP commands.
The LOAD-LOOKUP command defines an array containing a set of keys and values and loads it into memory. The LOOKUP command looks up a key in the array and returns the associated value. In some programs, this technique performs better than a conventional table join.
We can use LOAD-LOOKUP in the SETUP section or in a procedure. If used in the SETUP section, it is processed only once. If used in a procedure, it is processed each time it is encountered.
LOAD-LOOKUP retrieves two fields from the database: the KEY field and the RETURN_VALUE field. Rows are ordered by KEY and stored in an array. The KEY field must be unique and contain no null values.
When the LOOKUP command is used, the array is searched (by using a binary search) to find the RETURN_VALUE field corresponding to the KEY that is referenced in the lookup.
The following code example illustrates LOAD-LOOKUP and LOOKUP:
begin-setup
load-lookup
name=NAMES
table=EMPNAME
key=EMPLOYEE_ID
return_value=EMPLOYEE_NAME
end-setup
...
begin-select
BUSINESS_UNIT (+1,1)
EMPLOYEE_ID
lookup NAMES &EMPLOYEE_ID $EMPLOYEE_NAME
print $EMPLOYEE_NAME (,15)
from JOB
end-select
In this code example, the LOAD-LOOKUP command loads an array with the EMPLOYEE_ID and EMPLOYEE_NAME columns from the EMPNAME table. The lookup array is named NAMES. The EMPLOYEE_ID column is the key and the EMPLOYEE_NAME column is the return value. In the select paragraph, a LOOKUP on the NAMES array retrieves the EMPLOYEE_NAME for each EMPLOYEE_ID. This technique eliminates the need to join the EMPNAME table in the select.
If the JOB and EMPNAME tables were joined in the select (without LOAD-LOOKUP), the code would look like this:
begin-select
BUSINESS_UNIT (+1,1)
JOB.EMPLOYEE_IDproduct_code
EMPLOYEE_NAME (,15)
from JOB, EMPNAME
where JOB.EMPLOYEE_ID = EMPNAME.EMPLOYEE_ID
end-select
Whether a database join or LOAD-LOOKUP is faster depends on the program. LOAD-LOOKUP improves performance when:
• It is used with multiple select paragraphs.
• It keeps the number of tables being joined from exceeding three or four.
• The number of entries in the LOAD-LOOKUP table is small compared to the number of rows in the select, and they are used often.
• Most entries in the LOAD-LOOKUP table are used.
Note. You can concatenate columns if you want RETURN_VALUE to return more than one column. The concatenation symbol is database specific.
Improving SQL Performance with Dynamic SQL
We can use dynamic SQL in some situations to simplify a SQL statement and gain performance:
begin-select
BUSINESS_UNIT
from JOB, LOCATION_TBL
where JOB.BUSINESS_UNIT = LOCATION_TBL.BUSINESS_UNIT
and ($state = 'CA' and EFF_DATE > $start_date
or $state != 'CA' and TRANSFER_DATE > $start_date)
end-select
In this example, a given value of $state, EFF_DATE, or TRANSFER_DATE is compared to $start_date. The OR operator in the condition makes such multiple comparisons possible. With most databases, an OR operator slows processing. It can cause the database to perform more work than necessary.
However, the same work can be done with a simpler select. For example, if $state is ‘CA,’ the following select works:
begin-select
BUSINESS_UNIT
from JOB, LOCATION_TBL
where JOB.BUSINESS_UNIT = LOCATION_TBL.BUSINESS_UNIT
and EFF_DATE > $start_date
end-select
Dynamic SQL enables you to check the value of $state and create the simpler condition:
if $state = 'CA'
let $datecol = 'EFF_DATE'
else
let $datecol = 'TRANSFER_DATE'
end-if
begin-select
BUSINESS_UNIT
from JOB, LOCATION_TBL
where JOB.BUSINESS_UNIT = LOCATION_TBL.BUSINESS_UNIT
and [$datecol] > $start_date
end-select
The [$datecol] substitution variable substitutes the name of the column to be compared with $state_date. The select is simpler and no longer uses an OR operator. In most cases, this use of dynamic SQL improves performance.
Examining SQL Cursor Status
Because SQR programs select and manipulate data from a SQL database, it is helpful to understand how SQR processes SQL statements and queries.
SQR programs can perform multiple SQL statements. Moreover, the same SQL statement can be run multiple times.
When a program runs, a pool of SQL statement handles—called cursors—is maintained. A cursor is a storage location for one SQL statement; for example, SELECT, INSERT, or UPDATE. Every SQL statement uses a cursor for processing. A cursor holds the context for the execution of a SQL statement.
The cursor pool contains 30 cursors, and its size cannot be changed. When a SQL statement is rerun, its cursor can be immediately reused if it is still in the cursor pool. When an SQR program runs more than 30 different SQL statement, cursors in the pool are reassigned.
To examine how cursors are managed, use the -S command-line flag. This flag displays cursor status information at the end of a run.
The following information appears for each cursor:
Cursor #nn:
SQL =
Compiles = nn
Executes = nn
Rows = nn
The listing also includes the number of compiles, which vary according to the database and the complexity of the query. With Oracle, for example, a simple query is compiled only once. With SYBASE, a SQL statement is compiled before it is first run and recompiled for the purpose of validation during the SQR compile phase. Therefore, you may see two compiles for a SQL statement. Later when the SQL is rerun, if its cursor is found in the cursor pool, it can proceed without recompiling.
Avoiding Temporary Database Tables
Programs often use temporary database tables to hold intermediate results. Creating, updating, and deleting database temporary tables is a very resource-consuming task, however, and can hurt your program’s performance. SQR provides two alternatives to using temporary database tables.
The first alternative is to store intermediate results in an SQR array. The second is to store intermediate results in a local flat file. Both techniques can bring about a significant performance gain. You can use the SQR language to manipulate data stored in an array or a flat file.
These two methods are explained and demonstrated in the following sections. Methods for sorting data in SQR arrays or flat files are also explained.
Using and Sorting Arrays
An SQR array can hold as many records as can fit in memory. During the first pass, when records are retrieved from the database, you can store them in the array. Subsequent passes on the data can be made without additional database access.
The following code example retrieves records, prints them, and saves them into an array named
ADDRESS_DETAILS_ARRAY:
create-array name=ADDRESS_DETAILS_ARRAY size=1000
field=ADDRESSLINE1:char field=ADDRESSLINE2:char
field=PINCODE:char field=PHONE:char
let #counter = 0
begin-select
ADDRESSLINE1 (,1)
ADDRESSLINE2 (,7)
PINCODE (,24)
PHONE (,55)
position (+1)
put &ADDRESSLINE1 &ADDRESSLINE2 &PINCODE &PHONE into ADDRESS_DETAILS_ARRAY(#counter)
add 1 to #counter
from ADDRESS
end-select
The ADDRESS_DETAILS_ARRAY array has four fields that correspond to the four columns that are selected from the ADDRESS table, and it can hold up to 1,000 rows. If the ADDRESS table had more than 1,000 rows, it would be necessary to create a larger array.
The select paragraph prints the data. The PUT command then stores the data in the array. You could use the LET command to assign values to array fields, however the PUT command performs the same work, with fewer lines of code. With PUT, you can assign all four fields in one command.
The #counter variable serves as the array subscript. It starts with zero and maintains the subscript of the next available entry. At the end of the select paragraph, the value of #counter is the number of records in the array.
The next code example retrieves the data from ADDRESS_DETAILS_ARRAY and prints it:
let #i = 0
while #i < #counter get &ADDRESSLINE1 &ADDRESSLINE2 &PINCODE &PHONE from ADDRESS_DETAILS_ARRAY(#i) print $ADDRESSLINE1 (,1) print $ADDRESSLINE2 (,7) print $PINCODE (,24) print $PHONE (,55) position (+1) add 1 to #i end-while In this code example, #i goes from 0 to #counter-1. The fields from each record are moved into the corresponding variables: $ADDRESSLINE1, $ADDRESSLINE2, $PINCODE and $PHONE. These values are then printed. Using and Sorting Flat Files An alternative to an array is a flat file. You can use a flat file when the required array size exceeds the available memory. As is the case with an array, you may need a sorting utility that supports NLS. The code example in the previous section can be rewritten to use a file instead of an array. The advantage of using a file is that the program is not constrained by the amount of memory that is available. The disadvantage of using a file is that the program performs more input/output (I/O). However, it may still be faster than performing another SQL statement to retrieve the same data. This program uses the UNIX/Linux sort utility to sort the file by name. This example can be extended to include other operating systems. The following code example is rewritten to use the cust.dat file instead of the array: Program ex25b.sqr begin-program do main end-programbegin-procedure main ! ! Open cust.dat ! open 'cust.dat' as 1 for-writing record=80:vary begin-select ADDRESSLINE1 (,1) ADDRESSLINE2 (,7) PINCODE (,24) PHONE (55) position (+1) ! Put data in the file write 1 from &ADDRESSLINE1:30 &ADDRESSLINE1:30 &PINCODE:6 &PHONE:10 from ADDRESS order by PINCODE end-select position (+2) ! ! Close cust.dat close 1 ! Sort cust.dat by name ! call system using 'sort cust.dat > cust2.dat' #status
if #status <> 0
display 'Error in sort'
stop
end-if
!
! Print ADDRESS (which are now sorted by name)
!
open 'cust2.dat' as 1 for-reading record=80:vary
while 1 ! loop until break
! Get data from the file
read 1 into $ADDRESSLINE1:30 $ADDRESSLINE2:30 $PINCODE:6 $PHONE:10
if #end-file
break ! End of file reached
end-if
print $ADDRESSLINE1 (,1)
print $ADDRESSLINE2 (,7)
print $PINCODE (,24)
print $PHONE (,55)
position (+1)
end-while
!
! close cust2.dat
close 1
end-procedure ! main
The program starts by opening a cust.dat file:
open 'cust.dat' as 1 for-writing record=80:vary
The OPEN command opens the file for writing and assigns it file number 1. You can open as many as 12 files in one SQR program. The file is set to support records of varying lengths with a maximum of 80 bytes (characters). For this example, you can also use fixed-length records.
As the program selects records from the database and prints them, it writes them to cust.dat:
write 1 from &ADDRESSLINE1:30 &ADDRESSLINE2:30 &PINCODE:6 &PHONE:10
The WRITE command writes the four columns into file number 1—the currently open cust.dat. It writes the name first, which makes it easier to sort the file by name. The program writes fixed-length fields. For example, &ADDRESSLINE1:30 specifies that the name column uses exactly 30 characters. If the actual name is shorter, it is padded with blanks. When the program has finished writing data to the file, it closes the file by using the CLOSE command.
The file is sorted with the UNIX sort utility:
call system using 'sort cust.dat > cust2.dat' #status
The sort cust.dat > cust2.datis command sent to the UNIX system. It invokes the UNIX sort command to sort cust.dat and direct the output to cust2.dat. The completion status is saved in #status; a status of 0 indicates success. Because name is at the beginning of each record, the file is sorted by name.
Next, we open cust2.dat for reading. The following command reads one record from the file and places the first 30 characters in $ADDRESSLINE1:
read 1 into $ADDRESSLINE1:30 $ADDRESSLINE2:30 $PINCODE:6 $PHONE:10
The next two characters are placed in $PINCODE and so on. When the end of the file is encountered, the #end-file reserved variable is automatically set to 1 (true). The program checks for #end-file and breaks out of the loop when the end of the file is reached. Finally, the program closes the file by using the CLOSE command.
Creating Multiple Reports in One Pass
Sometimes you must create multiple reports that are based on the same data. In many cases, these reports are similar, with only a difference in layout or summary. Typically, you can create multiple programs and even reuse code. However, if each program is run separately, the database has to repeat the query. Such repeated processing is often unnecessary.
With SQR, one program can create multiple reports simultaneously. In this method, a single program creates multiple reports, making just one pass on the data and reducing the amount of database processing.
Tuning SQR Numerics
SQR for PeopleSoft provides three types of numeric values:
• Machine floating point numbers
• Decimal numbers
• Integers
Machine floating point numbers are the default. They use the floating point arithmetic that is provided by the hardware. This method is very fast. It uses binary floating point and normally holds up to 15 digits of precision.
Some accuracy can be lost when converting decimal fractions to binary floating point numbers. To overcome this loss of accuracy, you can sometimes use the ROUND option of commands such as ADD, SUBTRACT, MULTIPLY, and DIVIDE. You can also use the round function of LET or numeric edit masks that round the results to the needed precision.
Decimal numbers provide exact math and precision of up to 38 digits. Math is performed in the software. This is the most accurate method, but also the slowest.
You can use integers for numbers that are known to be integers. There are several benefits for using integers because they:
• Enforce the integer type by not allowing fractions.
• Adhere to integer rules when dividing numbers.
Integer math is also the fastest, typically faster than floating point numbers.
If you use the DECLARE-VARIABLE command, the -DNT command-line flag, or the DEFAULT-NUMERIC entry in the Default-Settings section of the PSSQR.INI file, you can select the type of numbers that SQR uses. Moreover, you can select the type for individual variables in the program with the DECLARE-VARIABLE command. When you select decimal numbers, you can also specify the needed precision.
Selecting the numeric type for variables enables you to fine-tune the precision of numbers in your program. For most applications, however, this type of tuning does not yield a significant performance improvement, so it's best to select decimal. The default is machine floating point to provide compatibility with older releases of the product.
Setting Processing Limits
Use a startup file and the Processing-Limits section of PSSQR.INI to define the sizes and limitations of some of the internal structures that are used by SQR. An -M command-line flag can specify a startup file whose entries override those in PSSQR.INI. If you use the -Mb command-line flag, then corresponding sections of the file are not processed. Many of these settings have a direct affect on memory requirements.
Tuning of memory requirements used to be a factor with older, 16-bit operating systems, such as Windows 3.1. Today, most operating systems use virtual memory and tuning memory requirements normally do not affect performance in any significant way. The only case in which you might need to be concerned with processing limit settings is with large SQR programs that exceed default processing limit settings. In such cases you must increase the corresponding settings
Buffering Fetched Rows
When a BEGIN-SELECT command is run, records are fetched from the database server. To improve performance, they are fetched in groups rather than one at a time. The default is groups of 10 records. The records are buffered, and a program processes these records one at a time. A database fetch operation is therefore performed after every 10 records, instead of after every single record. This is a substantial performance gain. If the database server is on another computer, then network traffic is also significantly reduced.
Modify the number of records to fetch together by using the -B command-line flag or, for an individual BEGIN-SELECT command, by using its -B option. In both cases, specify the number of records to be fetched together. For example -B100 specifies that records be fetched in groups of 100. This means that the number of database fetch operations is further reduced.
This feature is currently available with SQR for ODBC and SQR for the Oracle or SYBASE databases.
Running Programs on the Database Server
To reduce network traffic and improve performance, run SQR programs directly on the database server machine. The SQR server is available on many server platforms including Windows NT and UNIX/Linux.
SQR Programming Principles
• Develop all SQRs using Structured Programming
Structured Programming
A technique for organizing and coding computer programs in which a hierarch of modules issued, each having a single entry and a single exit point, and in which control is passed downward through the structure without unconditional branches to higher levels of the structure.
Structured programming is often associated with a top-down approach to design. In this way designers map out the large scale structure of a program in terms of smaller operations, implement and test the smaller operations, and then tie them together into a whole program.
• Pseudo-Code
o Flowchart the program logic
o Research and ask a few questions:
How much data will be pulled? Will it be100 rows or 1000 rows?
How many rows will come from each table?
What kind of data will be pulled? Student Data? Setup Data?
What does the key structure look like for the tables being pulled?
Is this table the parent or the child?
How important is this table?
What fields will be needed from this table? Are they available somewhere else?
o Write SQL and test in SQL Plus before coding SQR
• Use Linear Programming – easier to program and debug
• Comment
Summary
The following techniques can be used to improve the performance of your SQR programs:
• Simplify complex SELECT statements.
• Use LOAD-LOOKUP to simplify joins.
• Use dynamic SQL instead of a condition in a SELECT statement.
• Avoid using temporary database tables. Two alternatives to temporary
database tables are SQR arrays and flat files.
• Write programs that create multiple reports with one pass on the data.
• Use the most efficient numeric type for numeric variables (machine
floating point, decimal, or integer).
• Save compiled SQR programs and rerun them with SQR Execute.
• Adjust settings in the [Processing-Limits] section of SQR.INI or in a
startup file.
• Increase buffering of rows in SELECT statements with the -B flag.
• Execute programs on the database server machine.
• SQR Programming Principles
Whenever a program contains a BEGIN-SELECT, BEGIN-SQL, or EXECUTE command, it performs a SQL statement. Processing SQL statements typically consumes significant computing resources. Tuning
SQL statements typically yields higher performance gains than tuning any other part of your program.
This paper focuses on SQR tools for simplifying SQL statements and reducing the number of SQL executions. There are several techniques, including:
• Simplify a complex select paragraph.
• Use LOAD-LOOKUP to simplify joins.
• Improve SQL performance with dynamic SQL.
• Examine SQL cursor status.
• Avoid temporary database tables.
• Create multiple reports in one pass.
• Tune SQR numerics.
• Compile SQR programs and use SQR Execute.
• Set processing limits.
• Buffer fetched rows.
• Run programs on the database server.
Simplifying a Complex Select Paragraph
With relational database design, information is often normalized by storing data entities in separate tables. To display the normalized information, we must write a select paragraph that joins these tables together. With many database systems, performance suffers when you join more than three or four tables in one select paragraph.
With SQR, we can perform multiple select paragraphs and nest them. In this way, we can break a large join into several simpler selects. For example, we can break a select paragraph that joins the orders and the products tables into two selects. The first select retrieves the orders in which we are interested. For each order that is retrieved, a second select retrieves the products that were ordered. The second select is correlated to the first select by having a condition such as:
where order_num = &order_num
This condition specifies that the second select retrieves only products for the current order.
Similarly, if the report is based on products that were ordered, you can make the first select retrieve the products and make the second select retrieve the orders for each product.
This method improves performance in many cases, but not all. To achieve the best performance, we need to experiment with the different alternatives.
Using LOAD-LOOKUP to Simplify Joins
Database tables often contain key columns, such as a employee id or customer number. To retrieve a certain piece of information, we join two or more tables that contain the same column. For example, to obtain a product description, we can join the orders table with the products table by using the product_code column as the key.
With LOAD-LOOKUP, you can reduce the number of tables that are joined in one select. Use this command with LOOKUP commands.
The LOAD-LOOKUP command defines an array containing a set of keys and values and loads it into memory. The LOOKUP command looks up a key in the array and returns the associated value. In some programs, this technique performs better than a conventional table join.
We can use LOAD-LOOKUP in the SETUP section or in a procedure. If used in the SETUP section, it is processed only once. If used in a procedure, it is processed each time it is encountered.
LOAD-LOOKUP retrieves two fields from the database: the KEY field and the RETURN_VALUE field. Rows are ordered by KEY and stored in an array. The KEY field must be unique and contain no null values.
When the LOOKUP command is used, the array is searched (by using a binary search) to find the RETURN_VALUE field corresponding to the KEY that is referenced in the lookup.
The following code example illustrates LOAD-LOOKUP and LOOKUP:
begin-setup
load-lookup
name=NAMES
table=EMPNAME
key=EMPLOYEE_ID
return_value=EMPLOYEE_NAME
end-setup
...
begin-select
BUSINESS_UNIT (+1,1)
EMPLOYEE_ID
lookup NAMES &EMPLOYEE_ID $EMPLOYEE_NAME
print $EMPLOYEE_NAME (,15)
from JOB
end-select
In this code example, the LOAD-LOOKUP command loads an array with the EMPLOYEE_ID and EMPLOYEE_NAME columns from the EMPNAME table. The lookup array is named NAMES. The EMPLOYEE_ID column is the key and the EMPLOYEE_NAME column is the return value. In the select paragraph, a LOOKUP on the NAMES array retrieves the EMPLOYEE_NAME for each EMPLOYEE_ID. This technique eliminates the need to join the EMPNAME table in the select.
If the JOB and EMPNAME tables were joined in the select (without LOAD-LOOKUP), the code would look like this:
begin-select
BUSINESS_UNIT (+1,1)
JOB.EMPLOYEE_IDproduct_code
EMPLOYEE_NAME (,15)
from JOB, EMPNAME
where JOB.EMPLOYEE_ID = EMPNAME.EMPLOYEE_ID
end-select
Whether a database join or LOAD-LOOKUP is faster depends on the program. LOAD-LOOKUP improves performance when:
• It is used with multiple select paragraphs.
• It keeps the number of tables being joined from exceeding three or four.
• The number of entries in the LOAD-LOOKUP table is small compared to the number of rows in the select, and they are used often.
• Most entries in the LOAD-LOOKUP table are used.
Note. You can concatenate columns if you want RETURN_VALUE to return more than one column. The concatenation symbol is database specific.
Improving SQL Performance with Dynamic SQL
We can use dynamic SQL in some situations to simplify a SQL statement and gain performance:
begin-select
BUSINESS_UNIT
from JOB, LOCATION_TBL
where JOB.BUSINESS_UNIT = LOCATION_TBL.BUSINESS_UNIT
and ($state = 'CA' and EFF_DATE > $start_date
or $state != 'CA' and TRANSFER_DATE > $start_date)
end-select
In this example, a given value of $state, EFF_DATE, or TRANSFER_DATE is compared to $start_date. The OR operator in the condition makes such multiple comparisons possible. With most databases, an OR operator slows processing. It can cause the database to perform more work than necessary.
However, the same work can be done with a simpler select. For example, if $state is ‘CA,’ the following select works:
begin-select
BUSINESS_UNIT
from JOB, LOCATION_TBL
where JOB.BUSINESS_UNIT = LOCATION_TBL.BUSINESS_UNIT
and EFF_DATE > $start_date
end-select
Dynamic SQL enables you to check the value of $state and create the simpler condition:
if $state = 'CA'
let $datecol = 'EFF_DATE'
else
let $datecol = 'TRANSFER_DATE'
end-if
begin-select
BUSINESS_UNIT
from JOB, LOCATION_TBL
where JOB.BUSINESS_UNIT = LOCATION_TBL.BUSINESS_UNIT
and [$datecol] > $start_date
end-select
The [$datecol] substitution variable substitutes the name of the column to be compared with $state_date. The select is simpler and no longer uses an OR operator. In most cases, this use of dynamic SQL improves performance.
Examining SQL Cursor Status
Because SQR programs select and manipulate data from a SQL database, it is helpful to understand how SQR processes SQL statements and queries.
SQR programs can perform multiple SQL statements. Moreover, the same SQL statement can be run multiple times.
When a program runs, a pool of SQL statement handles—called cursors—is maintained. A cursor is a storage location for one SQL statement; for example, SELECT, INSERT, or UPDATE. Every SQL statement uses a cursor for processing. A cursor holds the context for the execution of a SQL statement.
The cursor pool contains 30 cursors, and its size cannot be changed. When a SQL statement is rerun, its cursor can be immediately reused if it is still in the cursor pool. When an SQR program runs more than 30 different SQL statement, cursors in the pool are reassigned.
To examine how cursors are managed, use the -S command-line flag. This flag displays cursor status information at the end of a run.
The following information appears for each cursor:
Cursor #nn:
SQL =
Compiles = nn
Executes = nn
Rows = nn
The listing also includes the number of compiles, which vary according to the database and the complexity of the query. With Oracle, for example, a simple query is compiled only once. With SYBASE, a SQL statement is compiled before it is first run and recompiled for the purpose of validation during the SQR compile phase. Therefore, you may see two compiles for a SQL statement. Later when the SQL is rerun, if its cursor is found in the cursor pool, it can proceed without recompiling.
Avoiding Temporary Database Tables
Programs often use temporary database tables to hold intermediate results. Creating, updating, and deleting database temporary tables is a very resource-consuming task, however, and can hurt your program’s performance. SQR provides two alternatives to using temporary database tables.
The first alternative is to store intermediate results in an SQR array. The second is to store intermediate results in a local flat file. Both techniques can bring about a significant performance gain. You can use the SQR language to manipulate data stored in an array or a flat file.
These two methods are explained and demonstrated in the following sections. Methods for sorting data in SQR arrays or flat files are also explained.
Using and Sorting Arrays
An SQR array can hold as many records as can fit in memory. During the first pass, when records are retrieved from the database, you can store them in the array. Subsequent passes on the data can be made without additional database access.
The following code example retrieves records, prints them, and saves them into an array named
ADDRESS_DETAILS_ARRAY:
create-array name=ADDRESS_DETAILS_ARRAY size=1000
field=ADDRESSLINE1:char field=ADDRESSLINE2:char
field=PINCODE:char field=PHONE:char
let #counter = 0
begin-select
ADDRESSLINE1 (,1)
ADDRESSLINE2 (,7)
PINCODE (,24)
PHONE (,55)
position (+1)
put &ADDRESSLINE1 &ADDRESSLINE2 &PINCODE &PHONE into ADDRESS_DETAILS_ARRAY(#counter)
add 1 to #counter
from ADDRESS
end-select
The ADDRESS_DETAILS_ARRAY array has four fields that correspond to the four columns that are selected from the ADDRESS table, and it can hold up to 1,000 rows. If the ADDRESS table had more than 1,000 rows, it would be necessary to create a larger array.
The select paragraph prints the data. The PUT command then stores the data in the array. You could use the LET command to assign values to array fields, however the PUT command performs the same work, with fewer lines of code. With PUT, you can assign all four fields in one command.
The #counter variable serves as the array subscript. It starts with zero and maintains the subscript of the next available entry. At the end of the select paragraph, the value of #counter is the number of records in the array.
The next code example retrieves the data from ADDRESS_DETAILS_ARRAY and prints it:
let #i = 0
while #i < #counter get &ADDRESSLINE1 &ADDRESSLINE2 &PINCODE &PHONE from ADDRESS_DETAILS_ARRAY(#i) print $ADDRESSLINE1 (,1) print $ADDRESSLINE2 (,7) print $PINCODE (,24) print $PHONE (,55) position (+1) add 1 to #i end-while In this code example, #i goes from 0 to #counter-1. The fields from each record are moved into the corresponding variables: $ADDRESSLINE1, $ADDRESSLINE2, $PINCODE and $PHONE. These values are then printed. Using and Sorting Flat Files An alternative to an array is a flat file. You can use a flat file when the required array size exceeds the available memory. As is the case with an array, you may need a sorting utility that supports NLS. The code example in the previous section can be rewritten to use a file instead of an array. The advantage of using a file is that the program is not constrained by the amount of memory that is available. The disadvantage of using a file is that the program performs more input/output (I/O). However, it may still be faster than performing another SQL statement to retrieve the same data. This program uses the UNIX/Linux sort utility to sort the file by name. This example can be extended to include other operating systems. The following code example is rewritten to use the cust.dat file instead of the array: Program ex25b.sqr begin-program do main end-programbegin-procedure main ! ! Open cust.dat ! open 'cust.dat' as 1 for-writing record=80:vary begin-select ADDRESSLINE1 (,1) ADDRESSLINE2 (,7) PINCODE (,24) PHONE (55) position (+1) ! Put data in the file write 1 from &ADDRESSLINE1:30 &ADDRESSLINE1:30 &PINCODE:6 &PHONE:10 from ADDRESS order by PINCODE end-select position (+2) ! ! Close cust.dat close 1 ! Sort cust.dat by name ! call system using 'sort cust.dat > cust2.dat' #status
if #status <> 0
display 'Error in sort'
stop
end-if
!
! Print ADDRESS (which are now sorted by name)
!
open 'cust2.dat' as 1 for-reading record=80:vary
while 1 ! loop until break
! Get data from the file
read 1 into $ADDRESSLINE1:30 $ADDRESSLINE2:30 $PINCODE:6 $PHONE:10
if #end-file
break ! End of file reached
end-if
print $ADDRESSLINE1 (,1)
print $ADDRESSLINE2 (,7)
print $PINCODE (,24)
print $PHONE (,55)
position (+1)
end-while
!
! close cust2.dat
close 1
end-procedure ! main
The program starts by opening a cust.dat file:
open 'cust.dat' as 1 for-writing record=80:vary
The OPEN command opens the file for writing and assigns it file number 1. You can open as many as 12 files in one SQR program. The file is set to support records of varying lengths with a maximum of 80 bytes (characters). For this example, you can also use fixed-length records.
As the program selects records from the database and prints them, it writes them to cust.dat:
write 1 from &ADDRESSLINE1:30 &ADDRESSLINE2:30 &PINCODE:6 &PHONE:10
The WRITE command writes the four columns into file number 1—the currently open cust.dat. It writes the name first, which makes it easier to sort the file by name. The program writes fixed-length fields. For example, &ADDRESSLINE1:30 specifies that the name column uses exactly 30 characters. If the actual name is shorter, it is padded with blanks. When the program has finished writing data to the file, it closes the file by using the CLOSE command.
The file is sorted with the UNIX sort utility:
call system using 'sort cust.dat > cust2.dat' #status
The sort cust.dat > cust2.datis command sent to the UNIX system. It invokes the UNIX sort command to sort cust.dat and direct the output to cust2.dat. The completion status is saved in #status; a status of 0 indicates success. Because name is at the beginning of each record, the file is sorted by name.
Next, we open cust2.dat for reading. The following command reads one record from the file and places the first 30 characters in $ADDRESSLINE1:
read 1 into $ADDRESSLINE1:30 $ADDRESSLINE2:30 $PINCODE:6 $PHONE:10
The next two characters are placed in $PINCODE and so on. When the end of the file is encountered, the #end-file reserved variable is automatically set to 1 (true). The program checks for #end-file and breaks out of the loop when the end of the file is reached. Finally, the program closes the file by using the CLOSE command.
Creating Multiple Reports in One Pass
Sometimes you must create multiple reports that are based on the same data. In many cases, these reports are similar, with only a difference in layout or summary. Typically, you can create multiple programs and even reuse code. However, if each program is run separately, the database has to repeat the query. Such repeated processing is often unnecessary.
With SQR, one program can create multiple reports simultaneously. In this method, a single program creates multiple reports, making just one pass on the data and reducing the amount of database processing.
Tuning SQR Numerics
SQR for PeopleSoft provides three types of numeric values:
• Machine floating point numbers
• Decimal numbers
• Integers
Machine floating point numbers are the default. They use the floating point arithmetic that is provided by the hardware. This method is very fast. It uses binary floating point and normally holds up to 15 digits of precision.
Some accuracy can be lost when converting decimal fractions to binary floating point numbers. To overcome this loss of accuracy, you can sometimes use the ROUND option of commands such as ADD, SUBTRACT, MULTIPLY, and DIVIDE. You can also use the round function of LET or numeric edit masks that round the results to the needed precision.
Decimal numbers provide exact math and precision of up to 38 digits. Math is performed in the software. This is the most accurate method, but also the slowest.
You can use integers for numbers that are known to be integers. There are several benefits for using integers because they:
• Enforce the integer type by not allowing fractions.
• Adhere to integer rules when dividing numbers.
Integer math is also the fastest, typically faster than floating point numbers.
If you use the DECLARE-VARIABLE command, the -DNT command-line flag, or the DEFAULT-NUMERIC entry in the Default-Settings section of the PSSQR.INI file, you can select the type of numbers that SQR uses. Moreover, you can select the type for individual variables in the program with the DECLARE-VARIABLE command. When you select decimal numbers, you can also specify the needed precision.
Selecting the numeric type for variables enables you to fine-tune the precision of numbers in your program. For most applications, however, this type of tuning does not yield a significant performance improvement, so it's best to select decimal. The default is machine floating point to provide compatibility with older releases of the product.
Setting Processing Limits
Use a startup file and the Processing-Limits section of PSSQR.INI to define the sizes and limitations of some of the internal structures that are used by SQR. An -M command-line flag can specify a startup file whose entries override those in PSSQR.INI. If you use the -Mb command-line flag, then corresponding sections of the file are not processed. Many of these settings have a direct affect on memory requirements.
Tuning of memory requirements used to be a factor with older, 16-bit operating systems, such as Windows 3.1. Today, most operating systems use virtual memory and tuning memory requirements normally do not affect performance in any significant way. The only case in which you might need to be concerned with processing limit settings is with large SQR programs that exceed default processing limit settings. In such cases you must increase the corresponding settings
Buffering Fetched Rows
When a BEGIN-SELECT command is run, records are fetched from the database server. To improve performance, they are fetched in groups rather than one at a time. The default is groups of 10 records. The records are buffered, and a program processes these records one at a time. A database fetch operation is therefore performed after every 10 records, instead of after every single record. This is a substantial performance gain. If the database server is on another computer, then network traffic is also significantly reduced.
Modify the number of records to fetch together by using the -B command-line flag or, for an individual BEGIN-SELECT command, by using its -B option. In both cases, specify the number of records to be fetched together. For example -B100 specifies that records be fetched in groups of 100. This means that the number of database fetch operations is further reduced.
This feature is currently available with SQR for ODBC and SQR for the Oracle or SYBASE databases.
Running Programs on the Database Server
To reduce network traffic and improve performance, run SQR programs directly on the database server machine. The SQR server is available on many server platforms including Windows NT and UNIX/Linux.
SQR Programming Principles
• Develop all SQRs using Structured Programming
Structured Programming
A technique for organizing and coding computer programs in which a hierarch of modules issued, each having a single entry and a single exit point, and in which control is passed downward through the structure without unconditional branches to higher levels of the structure.
Structured programming is often associated with a top-down approach to design. In this way designers map out the large scale structure of a program in terms of smaller operations, implement and test the smaller operations, and then tie them together into a whole program.
• Pseudo-Code
o Flowchart the program logic
o Research and ask a few questions:
How much data will be pulled? Will it be100 rows or 1000 rows?
How many rows will come from each table?
What kind of data will be pulled? Student Data? Setup Data?
What does the key structure look like for the tables being pulled?
Is this table the parent or the child?
How important is this table?
What fields will be needed from this table? Are they available somewhere else?
o Write SQL and test in SQL Plus before coding SQR
• Use Linear Programming – easier to program and debug
• Comment
Summary
The following techniques can be used to improve the performance of your SQR programs:
• Simplify complex SELECT statements.
• Use LOAD-LOOKUP to simplify joins.
• Use dynamic SQL instead of a condition in a SELECT statement.
• Avoid using temporary database tables. Two alternatives to temporary
database tables are SQR arrays and flat files.
• Write programs that create multiple reports with one pass on the data.
• Use the most efficient numeric type for numeric variables (machine
floating point, decimal, or integer).
• Save compiled SQR programs and rerun them with SQR Execute.
• Adjust settings in the [Processing-Limits] section of SQR.INI or in a
startup file.
• Increase buffering of rows in SELECT statements with the -B flag.
• Execute programs on the database server machine.
• SQR Programming Principles
Subscribe to:
Posts (Atom)
